




Context Platform for AI Agents
Without context, you’re paying for your agents to guess.
DataHub Cloud is the enterprise context platform that unifies technical metadata, business knowledge, and documentation into the context layer agents can rely on. Get accurate answers faster, keep context reliable long after go-live, and spend less on every inference.
Why is context so hard to get right?
Fragmented across silos.
Metric definitions, join logic, business glossaries, and institutional knowledge live in different tools. No agent can reconcile them without a single source of truth.
Manual creation that doesn’t scale.
Documenting context can take 15+ hours per table. At 500 business-critical tables, that’s years of effort — before you account for the fact that data changes constantly.
SME sign-off that never happens systematically.
AI can generate context drafts for you. But without a structured review process, domain experts never validate at scale. And agents act confidently on context that’s wrong.
Locked out of reach.
Well-documented context is only valuable if agents can reach it. Today, context sits in systems built for humans. All your agents need the same context delivered consistently, in real time, wherever they run.
DataHub Context Management Platform
 Genie
Genie
 Agent Development Kit
Agent Development Kit
ACTIVATION
LAYER
STORE
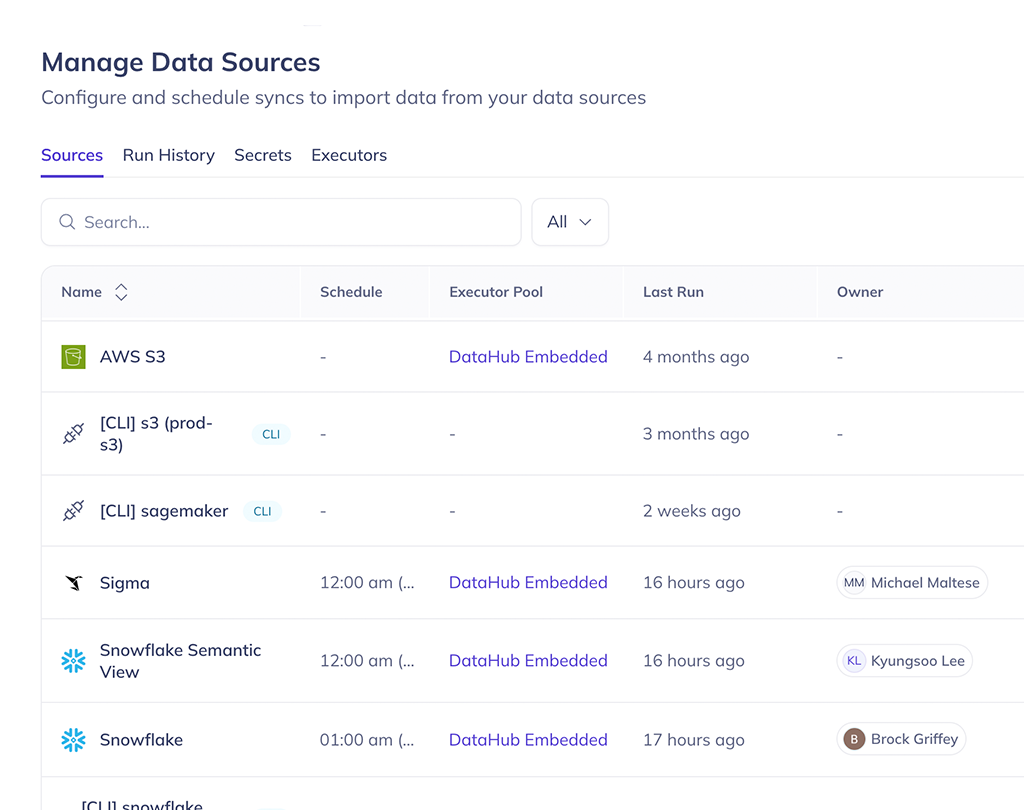
Unify the fragmented context agents depend on
Metric definitions live in dbt. Join logic is buried in Looker. Business knowledge sits in Notion and Confluence. Technical metadata lives in Snowflake. DataHub’s Context Ingestion connects all of it into a single context layer that updates in real time.
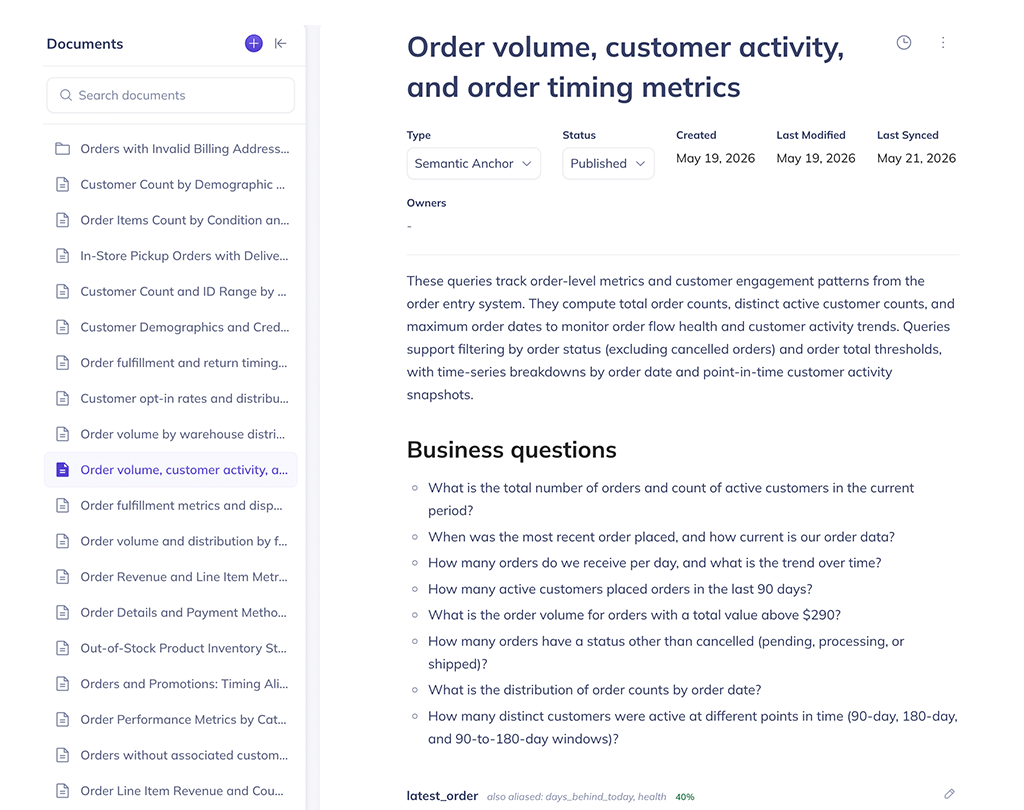
Eliminate the cold start problem
Instead of hours-long documentation workshops, DataHub’s Context Intelligence extracts semantic meaning from your existing query logs, dbt projects, and BI dashboards continuously — producing validated metric definitions and join patterns in days, not months.
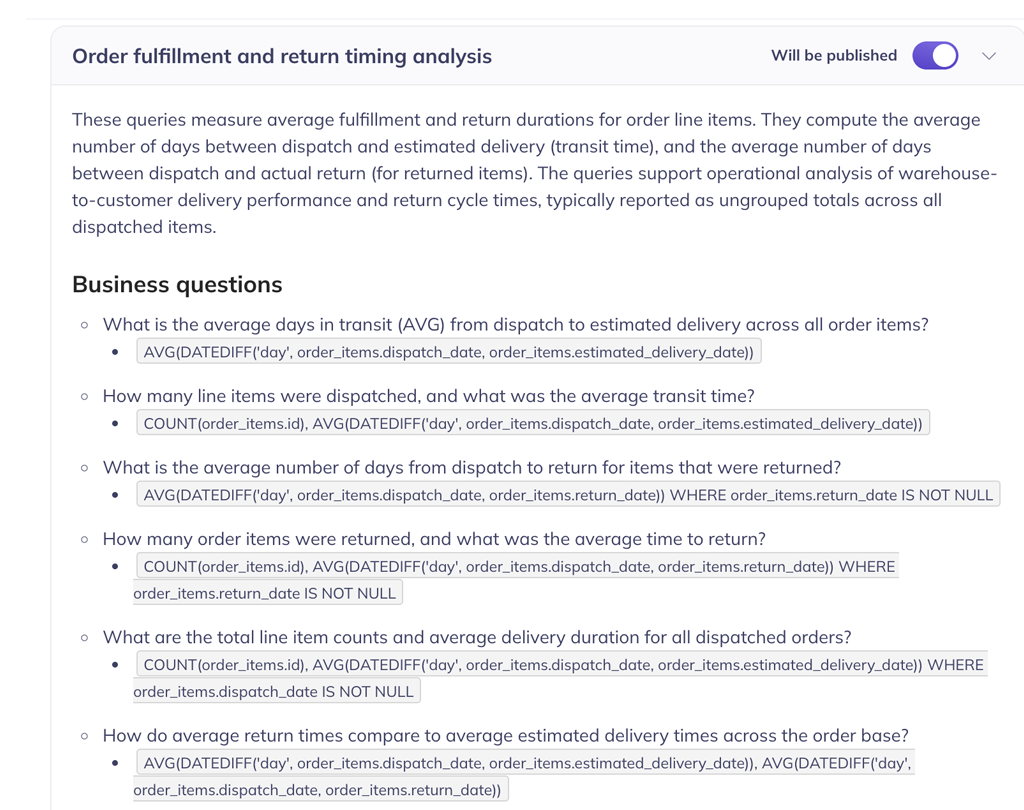
Maintain trusted, drift-free definitions
Auto-generated context is a starting point, not a finish line. DataHub’s Context Hub gives subject matter experts a dedicated workspace to confirm, refine, enrich, and resolve conflicting definitions, so agents stay accurate long after go-live.
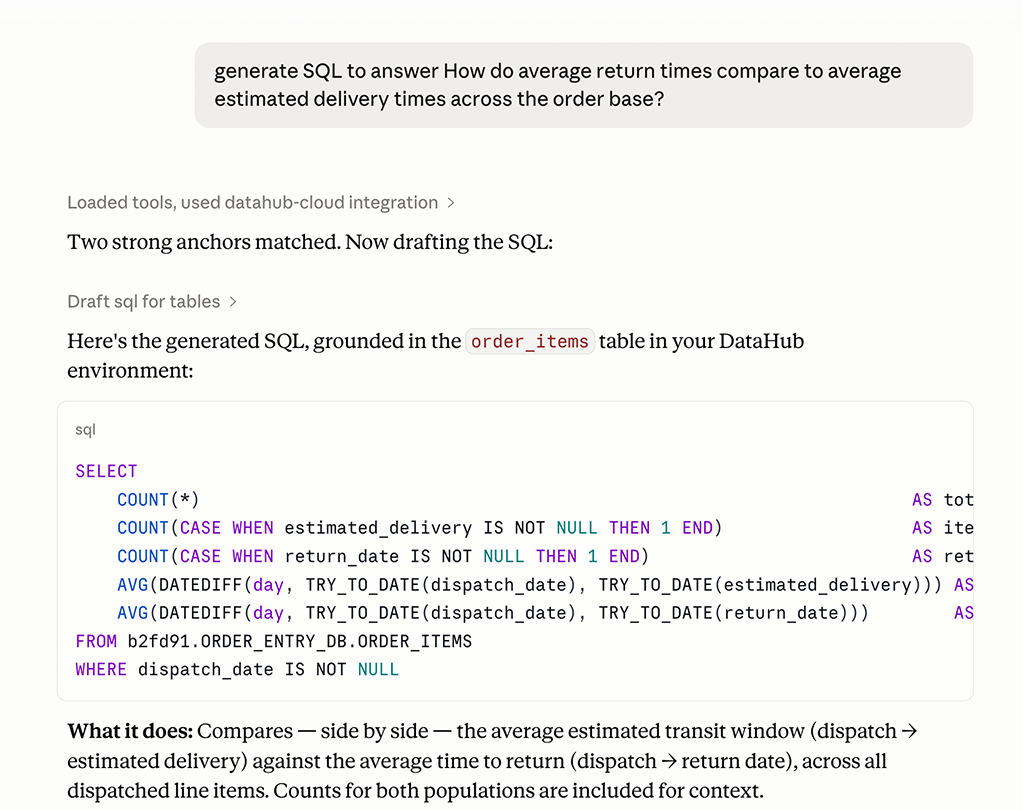
Expose the governed context layer wherever agents run
Connect Snowflake Intelligence, Databricks Genie, Claude, Cursor, and custom LangChain agents to a common and trusted source of context through a Context Activation layer that includes MCP, Agent Context Kit, skills, API/SDK, and personalized UX. Build once. Activate everywhere.
Reduce costs as agent usage scales
Agents without context spend tokens searching, guessing, and retrying. DataHub’s pre-validated context layer eliminates the guesswork loop. With precise direction from the start, agents reach the right answer faster, and save on MCP tool calls and token usage.
How teams use DataHub’s context platform to build agents that know
Data experts enable analytics agents without starting from scratch
Context Intelligence surfaces the gold buried in years of analytic history, extracting semantic meaning, metric definitions, and join patterns automatically and validating them through the Context Hub.

Business users stop second-guessing agent outputs
Business users get accurate, reliable agent responses they can act on without verification. Every response draws from SME-validated context extracted from your organization’s actual query history, not the model’s best guess.

Data/ML platform teams eliminate context fragmentation and drift
One continuously synced context layer unifies fragmented metadata, business definitions, and unstructured documentation across your org. When a definition changes upstream, every agent gets the latest version immediately.

Real context management results for enterprise teams
Pinterest turned 400,000 ungoverned tables into its #1 AI agent

The most effective systems carry forward what an organization has already learned and make that knowledge more usable for others. That’s the opportunity for DataHub — and for all of us.

Challenge
400,000+ ungoverned tables and institutional knowledge buried in Slack threads. Analysts spent hours reverse-engineering which table was current, trustworthy, and safe to use.
Solution
DataHub became Pinterest’s context layer — governing 100,000 curated assets and indexing analyst query history by intent so agents retrieve answers grounded in real institutional knowledge, not guesswork.
Impact
The Analytics Agent became Pinterest’s most-used agent: 10x the usage of the next agent, trusted answers in minutes, and a 70% reduction in manual documentation effort.
Built to meet enterprise context platform requirements
Accurate, reliable agents from day one
- Eliminate cold start with auto-generated context from query logs
- Resolve conflicting metric definitions before agents act on them
- Index analyst query intent so agents improve with every interaction
- Deliver deterministic, auditable answers grounded in validated context
Context that stays current and trusted over time
- Sync metadata from 100+ sources in real time
- Detect and route context drift to SMEs automatically
- Validate AI-proposed context through low-friction SME review
- Activate governed context across every agent surface at once
Enterprise scale and security
- 100+ pre-built connectors across warehouses, BI tools, and orchestrators
- SOC 2 Type II certified infrastructure with 99.5% uptime SLA
- Role-based access controls and single sign-on
- Trusted by 3,000+ organizations including Pinterest, Miro, and Netflix
FAQs
What is a context platform and how does it differ from a data catalog?
A data catalog indexes structured metadata about data assets — schemas, lineage, ownership, quality metrics — and delivers it to humans through a portal interface. A context platform unifies that metadata with the unstructured organizational knowledge that gives it meaning: runbooks, decision logs, business glossaries, and policies. The result is a unified context layer that serves both humans and AI agents. The distinction is architectural, not a checklist of features: A data catalog is a tool; a context platform is infrastructure. For a full breakdown of where the two diverge, see our post on context platform vs. data catalog.
How does DataHub deliver context to AI agents in real time?
DataHub uses an event-driven architecture that continuously syncs metadata from 100+ data sources as changes occur, rather than relying on scheduled batch ingestion. The DataHub MCP Server exposes the resulting context graph to any MCP-compatible AI tool — including Claude, Cursor, and Windsurf — through a standardized interface agents can query at machine speed. The Agent Context Kit provides additional SDKs and native integrations for platforms like Snowflake Intelligence, LangChain, and Google ADK. Agents receive not just schema, but lineage, ownership, quality signals, and linked documentation in a single governed response. For example, when a Notion page is updated, DataHub reflects that change in the context layer in near real-time. Every AI system querying it gets the latest version, not last week’s snapshot.
What kinds of context does DataHub manage?
DataHub manages the three main layers of context.
- Technical context is the structural foundation: schemas, column types, table relationships, data lineage, transformation logic, ownership, and dependency graphs.
- Operational context is the behavioral layer: query patterns, usage frequency, freshness SLAs, quality scores, incident history, and performance metrics.
- Business context is the human knowledge layer: business glossary definitions, domain classifications, governance policies, runbooks, decision logs, and the organizational knowledge that explains why data is structured the way it is — authored natively in DataHub or ingested from Notion and Confluence.
All three layers are indexed in a single queryable context graph and served to both humans and AI agents from the same governed source of truth. For a deeper look at the distinction between technical metadata and business context, see our post on business context vs. technical metadata.
What’s the difference between context management and context engineering?
Context engineering is the practice of curating what goes into a single AI agent’s context window at inference time: selecting retrieved documents, managing memory, orchestrating tool calls, and optimizing what the model sees for a specific task. Context management is the enterprise-wide capability that makes context engineering possible at scale. Where context engineering asks “what does this agent need to know right now?”, context management asks “how does every agent across the organization access trusted, governed, consistent context?” Context engineering solves the context problem within a single application. Context management solves it across the enterprise. For a full breakdown of where the two disciplines diverge, see our post on context engineering vs. context management.
What’s the difference between context management and RAG?
Context management and RAG operate at different layers of the stack. RAG is a retrieval pattern that runs on top of context management infrastructure. You still need it to bring context into the model’s context window. Context management is the enterprise infrastructure that ensures what RAG retrieves is discoverable, trustworthy, governed, and consistent across the organization. RAG is a technique. Context management is the foundation that makes the technique reliable at scale. For a deeper look, see our post on RAG vs. context management.
Does DataHub push context to AI agents, or do agents pull it?
Agents pull context from DataHub on demand through the MCP Server, APIs, skills, and SDKs. DataHub does not push context to agents at query time; instead, it maintains a continuously synchronized context layer that agents query when they need it. Agents can also write back to the context graph — adding tags, updating descriptions, assigning ownership — as part of governed workflows. The pull design is intentional: agents need selective context based on what a user is asking. Pushing everything upfront would be noise. Agents pull exactly what they need, when they need it.
Is the DataHub context platform open source?
DataHub Core, the open-source project that powers the platform, is freely available and maintained by a community of 15,000+ members. DataHub Cloud is the enterprise-managed offering built on that foundation, adding managed infrastructure, enterprise governance, agent-ready delivery via the MCP Server and Agent Context Kit, and the scale and SLA guarantees production deployments require. Organizations can start with the open-source project and move to DataHub Cloud as their context management needs grow.
How does DataHub integrate with our existing AI stack?
DataHub integrates at two layers.
- On the data side, pre-built connectors ingest metadata from 100+ systems, including Snowflake, Databricks, dbt, Looker, Airflow, and more, alongside documentation from Notion and Confluence.
- On the agent side, the DataHub MCP Server connects to any MCP-compatible tool, including Claude, Cursor, and Windsurf, while the Agent Context Kit provides native integrations for LangChain, Snowflake Intelligence, and Google ADK. DataHub also exposes the context graph via REST and GraphQL APIs for teams with custom agent frameworks, so it fits into existing infrastructure rather than replacing it.
How does DataHub handle sensitive data and access control for AI agents?
DataHub enforces fine-grained access controls at the context layer, before context reaches any agent. Policies govern which agents and service accounts can access which datasets, columns, business terms, and sensitivity-classified fields. The same policy engine that governs human access applies to every agent request. This means an agent not authorized to see PII-tagged columns cannot surface them, regardless of how the request is framed. Every context access is logged with provenance metadata, creating the audit trail compliance teams require under GDPR, HIPAA, and emerging AI regulations.
Why are enterprises investing in context platforms in 2026?
Agentic AI is moving from pilot to production, and the gap between the two is almost always an infrastructure gap, not a model gap. According to the State of Context Management Report 2026, 82% of IT and data leaders agree that agentic AI cannot reach production value without a context platform. The same report found 61% frequently delay AI initiatives due to lack of trusted data, and 57% duplicate AI efforts across departments because teams can’t find or agree on authoritative context. Prompt engineering and RAG alone don’t solve fragmentation, governance, freshness, or provenance — and those are the gaps that block production deployment.
What makes DataHub better than other context platforms?
Most context platforms give agents a path to your data. DataHub gives agents a reason to trust it. The platform is built around four purpose-built capabilities that work as a system:
- Context Ingestion unifies metadata from across your stack — Snowflake, dbt, Looker, Confluence, and more — into a single context graph automatically, eliminating the manual stitching that fragments context across teams.
- Context Intelligence continuously extracts semantic meaning from query logs, BI dashboards, and dbt projects to auto-generate context documents, so you’re not starting from a blank slate.
- Context Hub gives domain experts a structured, low-friction review queue where they confirm and refine AI-proposed context rather than create it from scratch.
- Context Activation delivers that validated context to every agent in your ecosystem — Snowflake Intelligence, Databricks Genie, Claude, Cursor, custom LangChain agents — through MCP, SDKs, and APIs from a single governed source.
The result is consistent, deterministic answers across every agent, without rebuilding context engineering pipelines for each one. In production, DataHub customers have seen a 2x improvement in analytics agent accuracy and a 60x improvement in speed of answering analytical questions.
Additional Resources

Context Management Hub
Context management is the organization-wide capability to reliably deliver the most relevant data to AI context windows, enabling governed, enterprise-scale deployment of agents. It…

Context Management Is the Missing Piece in the Agentic AI Puzzle
Context management gives AI agents secure, reliable access to enterprise data. Learn what it is and how to implement it.

Building Reliable Data Foundations for AI: A Live Session with DataHub Cloud
Experience DataHub Cloud's platform for unified data discovery, observability, and governance across your entire data stack.