




Data Catalog for Humans
Context Platform for AI
DataHub Cloud creates trusted context about enterprise data and enables intelligent decision making by humans and AI agents
Trusted by enterprise data teams around the world
IDC, “The Business Value of DataHub Cloud,” March 2026, sponsored by DataHub
Get hands-on with DataHub Cloud, on your schedule.
DataHub Cloud helps thousands of teams power reliable, AI-ready data. Now, you can see it in action—on your own terms.
Your data catalog wasn’t built for this.

Traditional catalogs were built for batch reporting and static warehouses. Not streaming data, complex data stacks, or production AI.
The cost shows up everywhere:
- Data engineers deploy blind — no visibility into what breaks when they change schemas
- Data analysts waste hours debugging anomalies in dashboards that were already stale
- Data scientists lose valuable hours hunting for reliable data across fragmented, undocumented systems
- Compliance teams audit manually while production changes flow past them unchecked
- Agents operating with incomplete context start guessing, get lost in schemas, wander through dev branches, and end up generating the wrong answer. Confidently.
How DataHub Cloud solves
what legacy catalogs can’t
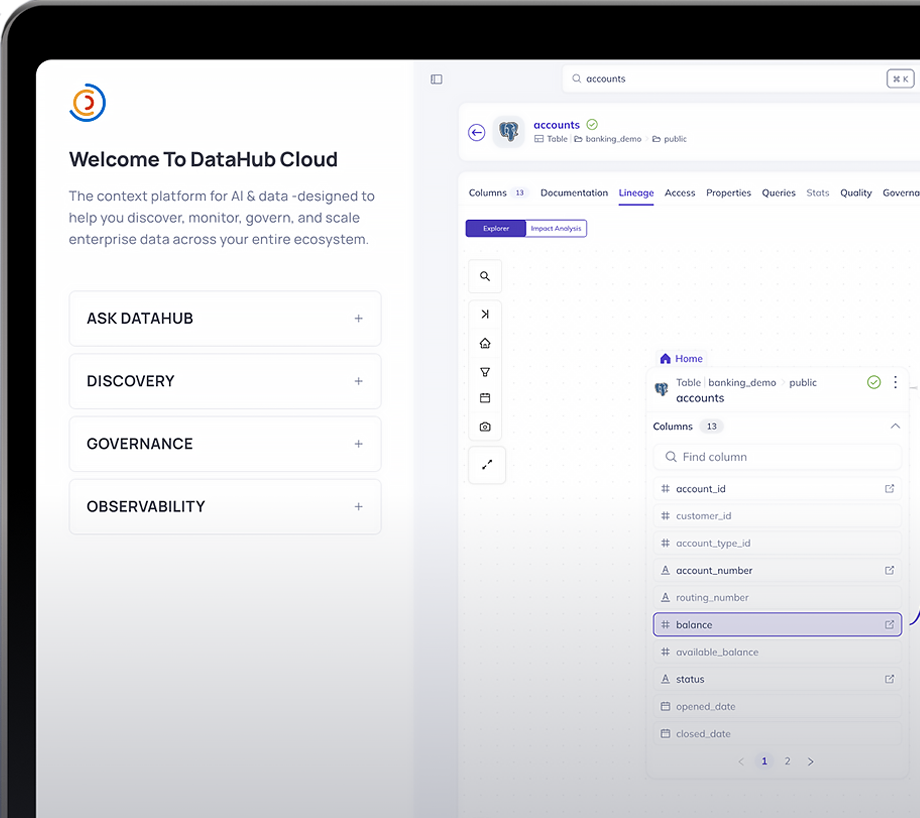
Discovery in seconds, not days.
Accelerate discovery with conversational search and automated documentation.
Instant data debugging.
Turn hours-long investigations into rapid resolution with cross-platform data lineage and AI-powered debugging.
Governance without the overhead.
Maintain compliance at scale with continuous monitoring and AI-driven quality checks.
Agentic answers you can trust.
Deliver consistent, deterministic answers grounded in validated context, not probabilistic guesses.

Find and understand data 10x faster.
Break down data silos with conversational data discovery. The Ask DataHub chat agent finds trusted data through natural language questions.
Explore Data Discovery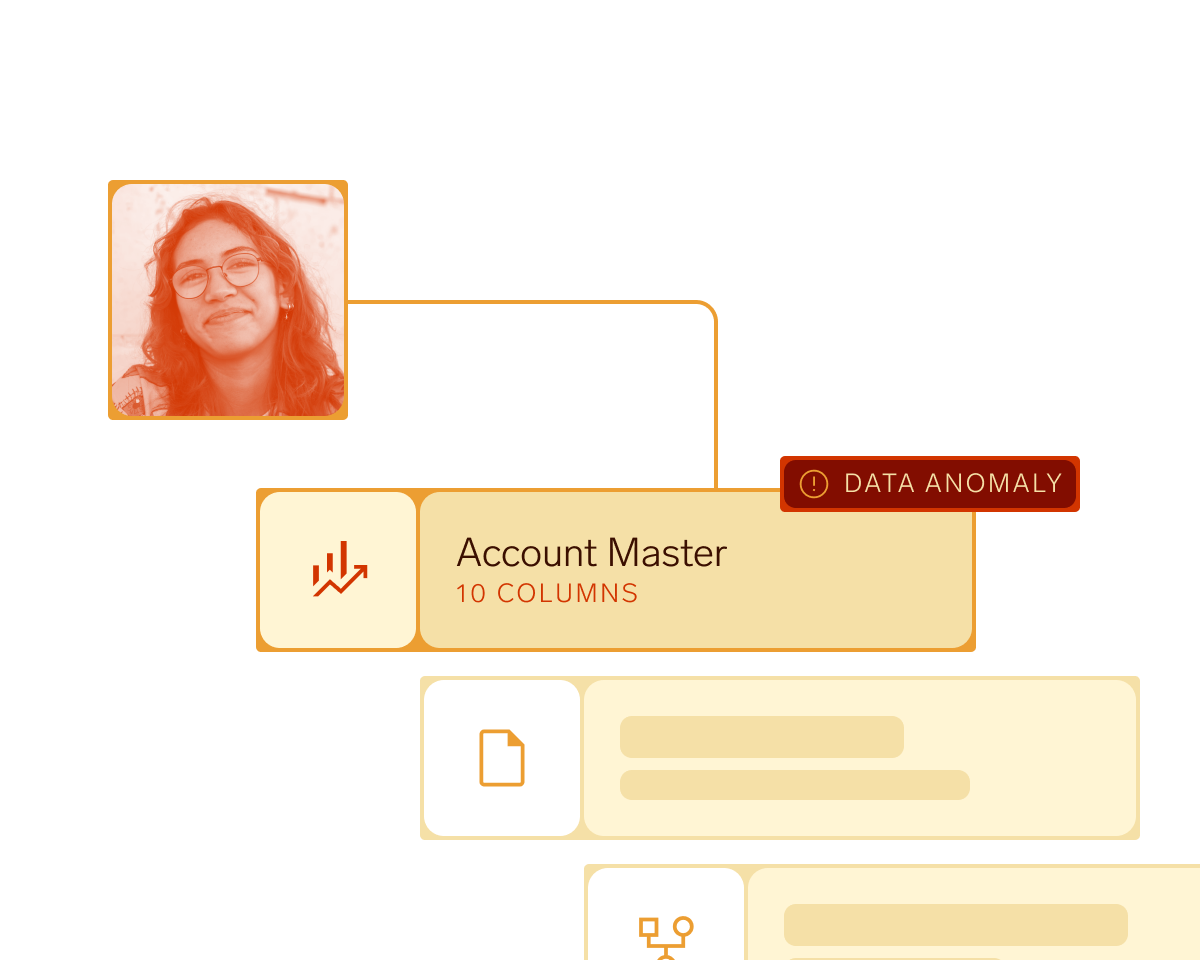
Reduce data incidents by 48%.
Detect and resolve quality issues before they impact production. Automated anomaly detection and quality checks keep data reliable.
Explore Data Observability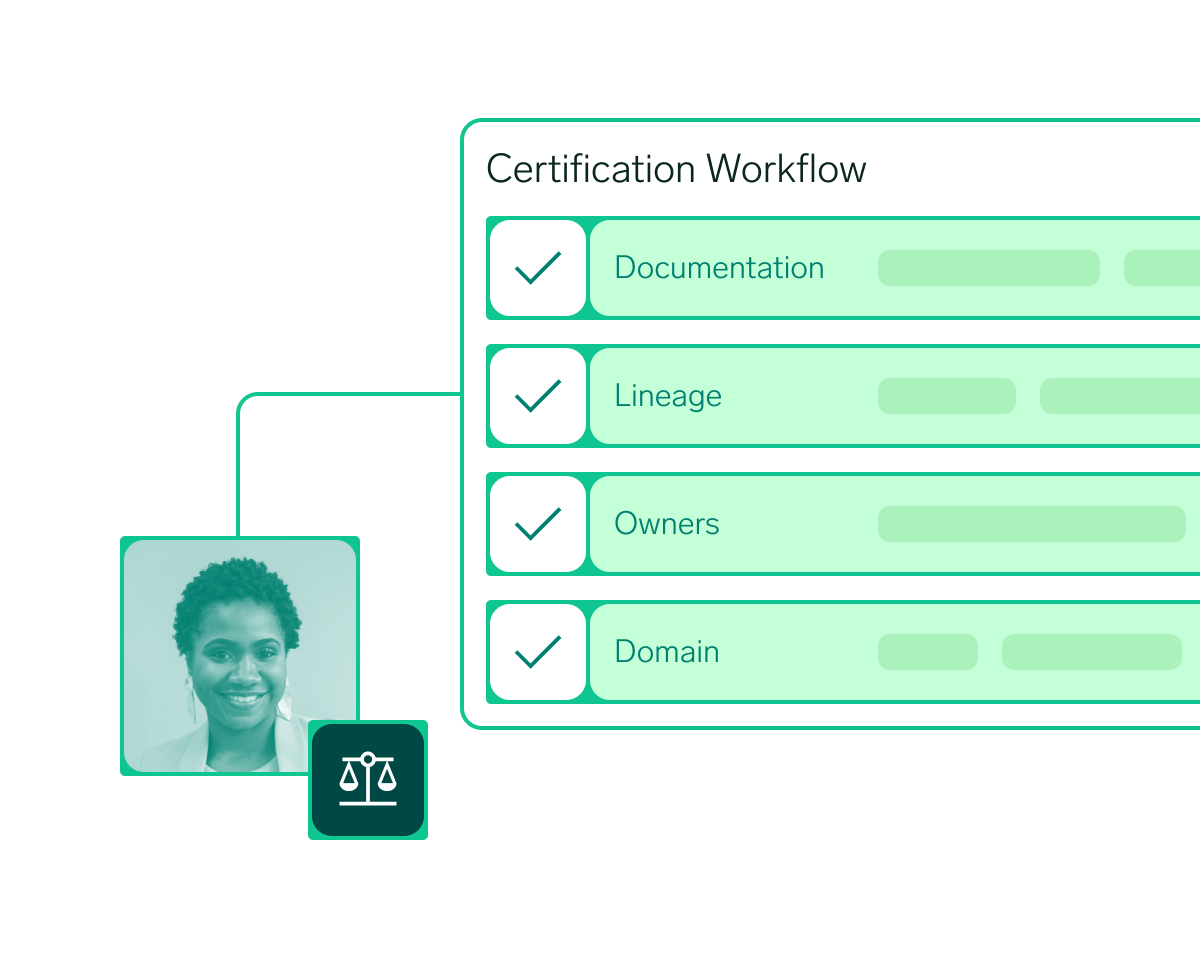
Reduce risk of compliance failure by a third.
Operationalize AI readiness with automated compliance. Set metadata tests, track certification workflows, and maintain enterprise-wide visibility into data health.
Explore Data Governance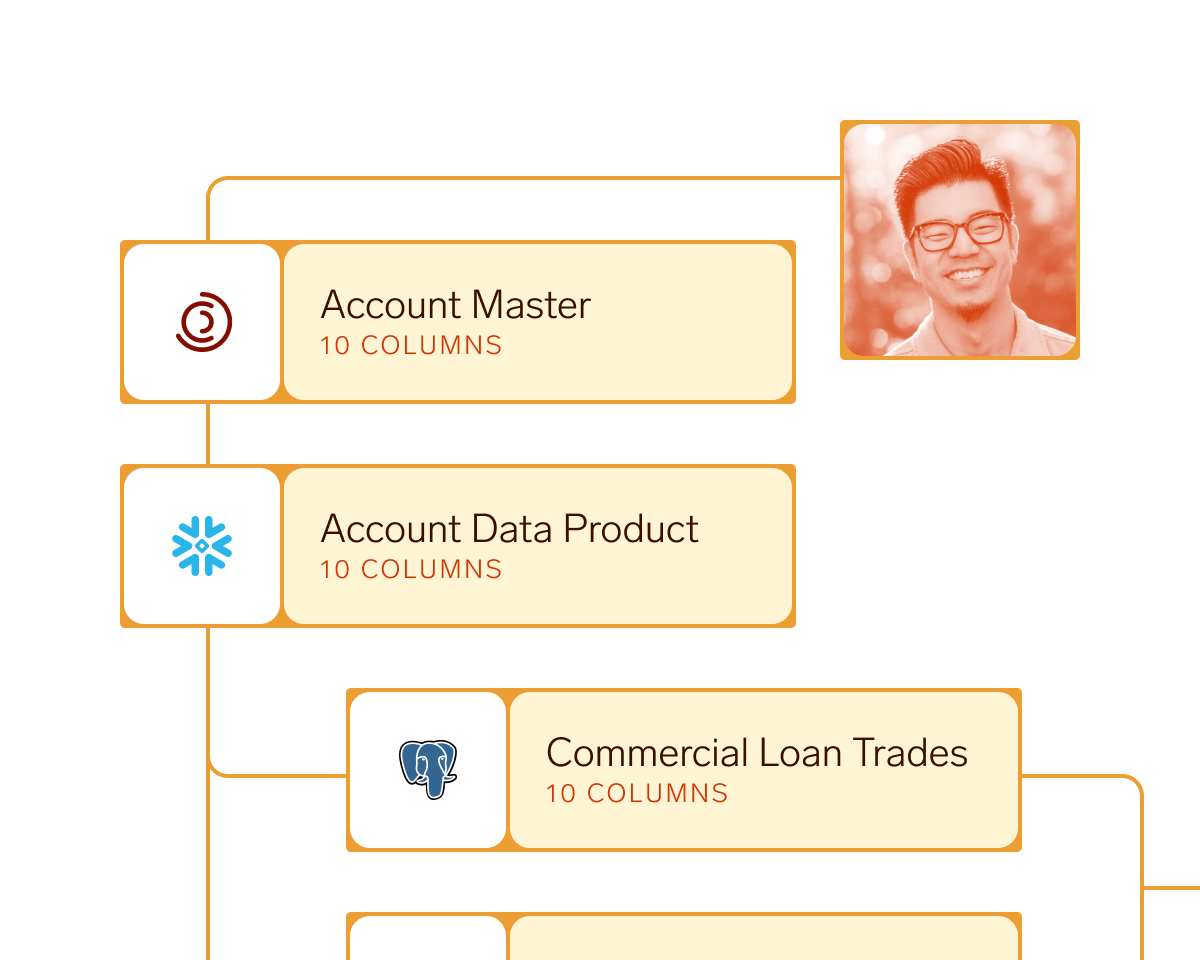
Get 75% more datasets with complete lineage.
Understand the true impact of changes before you make them. Column-level lineage traces data flows from source systems through transformations to downstream AI models and business applications.
Explore Data Lineage
Scale operations with 18% more productivity.
Free your team from repetitive metadata management tasks. AI documentation generation, intelligent glossary classification, and a hosted MCP Server automate data catalog maintenance.
Explore AI-powered Data Management
Deliver 2x accuracy for analytics agents.
Unify technical metadata, business knowledge, and documentation into the context layer agents can rely on. Get accurate answers faster, keep context reliable long after go-live, and spend less on every inference.
Explore Context Management

Built on proven open-source innovation
#1
OPEN-SOURCE DATA CATALOG WORLDWIDE
3,000+
ORGANIZATIONS USING DATAHUB
3M+
MONTHLY PYPI DOWNLOADS
15,000+
COMMUNITY MEMBERS COLLABORATING GLOBALLY
Ready to see DataHub Cloud in action?
Let us show you how it works.
Book a demo with our team.
FAQs
How does a data catalog accelerate AI and machine learning initiatives?
Enterprise data catalog solutions eliminate the manual discovery work that dominates ML engineering cycles. DataHub provides several capabilities that directly shorten AI development timelines:
- Feature reuse through discovery: Search across features, training datasets, and model inputs to find existing pipelines. Proactive discovery prevents redundant feature engineering and ensures consistent definitions across models.
- Lineage-based impact analysis: Trace column-level lineage from raw source data through transformation logic to features, training sets, and production models. Your teams can understand exactly what upstream changes affect which ML models.
- Automated quality validation: Configure assertion-based checks on training data freshness, completeness, and schema stability. With automated data observability, you can catch data drift and quality degradation before models consume corrupted inputs.
These capabilities shift engineering capacity from data archaeology to model experimentation. Teams use DataHub to reduce feature discovery time from days to minutes while maintaining the audit trails and data governance controls that production AI systems require at scale.
How does DataHub benefit enterprise organizations with complex data ecosystems?
DataHub unifies discovery, observability, and governance in a single platform—replacing the disconnected tools and manual processes enterprises used to manage these capabilities separately.
Modern enterprises like Netflix, Visa, and Apple deploy DataHub to solve three operational problems:
- Find data faster across fragmented systems: Search for enterprise data assets, owners, and documentation across Snowflake, Databricks, dbt, Airflow, and 100+ integrations—without switching tools or hunting through Slack channels.
- Catch data quality issues before they break downstream systems: Column-level lineage maps dependencies from source to BI dashboards while automated assertions detect freshness, schema, and volume anomalies—so you see exactly what breaks when something fails.
- Scale governance without slowing teams down: Automated policies, access controls, and compliance tags apply consistently across platforms—maintaining audit trails without manual tagging or blocking deployments.
DataHub consolidates three critical data platform functions into a unified platform that scales with organizational complexity. Enterprises use DataHub to eliminate the integration overhead and context-switching that legacy point solutions create across daily pipeline deployments.
Does DataHub support automated metadata ingestion?
Yes. DataHub ingests metadata automatically through event-driven connectors that capture changes across your data stack—without manual cataloging work.
This means your data catalog tools stay current as pipelines deploy, tables get created, and schemas change. Engineering teams focus on building data products instead of updating documentation.
Does DataHub integrate with modern data stacks like Snowflake, Databricks, dbt, and Airflow?
Yes. DataHub connects to Snowflake, Databricks, dbt, Airflow, and 100+ platforms across your data stack. Automated ingestion captures lineage, schema changes, and usage patterns without manual setup.
DataHub operates through scheduled ingestion or event-driven streams—both options keep your data catalog current without impacting source system performance or changing how your teams work.
How does DataHub help solve data provenance and lineage uncertainty?
DataHub captures column-level lineage automatically across your data ecosystem—replacing the ad hoc pings and institutional knowledge that disappear when pipelines change or engineers leave.
Modern data teams use DataHub to answer critical questions before making changes:
- What breaks if I modify this table? Trace which dashboards, models, and datasets depend on specific columns—so you know exactly what breaks when you change a schema or deprecate a field.
- Where did bad data come from? Follow lineage upstream from a broken dashboard to find which transformation or source table introduced the issue—cutting incident resolution from hours to minutes.
- How do my assets connect across tools? Visualize end-to-end flows from raw data sources through transformations to dashboards‚Äîeven when those tools don’t share lineage natively.
This shifts teams from reactive troubleshooting to proactive change management. Organizations like Chime and MYOB use DataHub to validate changes before deployment, preventing the cascading failures that happen when you can’t see how data moves through
Does DataHub allow for continuous compliance monitoring?
Yes. DataHub monitors compliance continuously.
Set your data governance requirements once, then track them across your entire data catalog:
- Compliance Forms track certification progress: Define requirements for PII classification, data certification, and ownership assignment. DataHub shows completion rates by domain and surfaces which assets are missing required fields.
- Data Contracts catch violations in real time: Bundle assertions for freshness, schema stability, and quality into enforceable contracts. Each assertion runs automatically and flags failures immediately through Slack, email, or dashboards.
- Scheduled checks detect drift before audits do: Configure custom monitors that run on intervals to catch missing documentation, stale ownership, or policy violations—so you fix issues before compliance reviews find them.
When violations occur, teams get immediate Slack and email alerts while dashboards track compliance trends across your organization. Try the DataHub
How can DataHub help reduce data infrastructure costs?
DataHub tracks usage patterns across your data platform to show where you’re wasting money on unused or duplicate assets.
DataHub helps you cut infrastructure costs by:
- Finding assets nobody uses: Query-level tracking shows which tables, dashboards, and pipelines had zero reads in the past 30, 60, or 90 days—so you can delete them and reclaim storage.
- Spotting duplicate datasets: Metadata analysis flags similar tables across teams—eliminating the storage and compute you waste rebuilding the same data in different warehouses.
- Aligning storage costs with actual usage: Usage metrics show which assets get queried daily versus monthly—so you can move cold data to cheaper storage and keep hot data on expensive compute.
Teams like DPG Media save 25% monthly on data warehousing costs by identifying the tables and pipelines that deliver zero business value.
How does DataHub improve data quality and reliability?
DataHub catches data quality issues before they break downstream dashboards and models—shifting teams from firefighting incidents to preventing them.
DataHub helps teams improve data reliability by:
- Validating quality automatically: Configure assertions for freshness, schema stability, null rates, and custom business rules. Run checks on schedules or when data changes to catch issues before analysts or ML models consume bad data.
- Getting alerts when data breaks: Pass/fail indicators show up directly in the data catalog with immediate Slack and email notifications—so you fix issues in minutes instead of discovering them hours later when dashboards fail.
- Guiding teams toward reliable data: Data health scores combine assertion results, usage frequency, and documentation completeness‚Äîso analysts pick assets that won’t break their reports.
Use DataHub to maintain SLAs on critical datasets and surface quality signals that prevent teams from building on unreliable data.
Can DataHub help automate PII tracking across our data systems for GDPR and CCPA compliance?
Yes. DataHub detects and tags PII automatically across your data platform‚Äîeliminating the manual audits that can’t keep up with GDPR and CCPA requirements.
DataHub helps teams automate compliance by:
- Classifying PII without manual tagging: AI analyzes column names, descriptions, and sample values to automatically suggest classifications from your glossary‚Äîdetecting PII like email addresses, phone numbers, and financial identifiers based on your organization’s defined terms.
- Applying tags consistently as schemas change: Approved PII classifications propagate across all instances of sensitive data—so GDPR and CCPA tags stay current when pipelines evolve or new tables get created.
- Tracking PII movement for audits: Cross-platform lineage maps how sensitive data flows from source systems through transformations to BI dashboards—providing the audit trails regulators require.
Use DataHub to see where PII lives, how it moves through pipelines, and which systems need enhanced access controls or retention policies.
Additional Resources

Context Platform ROI: The Real Cost (and the Hidden One You’re Already Paying)
Context platform ROI, measured. IDC's five categories of hidden spend most organizations are already paying without knowing it.

Context Management Hub
Context management is the organization-wide capability to reliably deliver the most relevant data to AI context windows, enabling governed, enterprise-scale deployment of agents. It…

Context Management Is the Missing Piece in the Agentic AI Puzzle
Context management gives AI agents secure, reliable access to enterprise data. Learn what it is and how to implement it.