Data Observability Platform for End-to-End Data Trust
Your engineers shouldn’t have to firefight data quality issues. DataHub Cloud delivers automated monitoring and instant root cause analysis. Catch issues before dashboards break, not after tickets pile up.

From firefighting to prevention in one platform
Proactively monitor data quality
Define schema, freshness, volume, and custom quality checks that run automatically across hundreds of columns. Smart alerts fire to owners when data deviates from expected patterns with complete lineage and suggested actions that accelerate resolution.
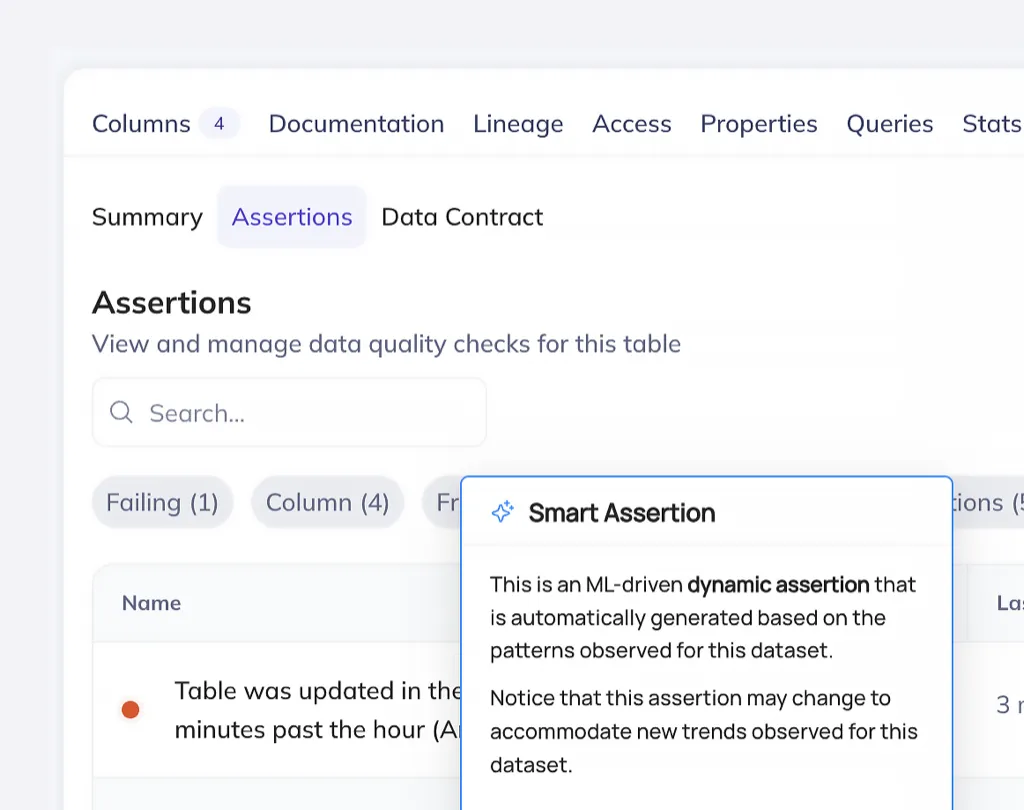
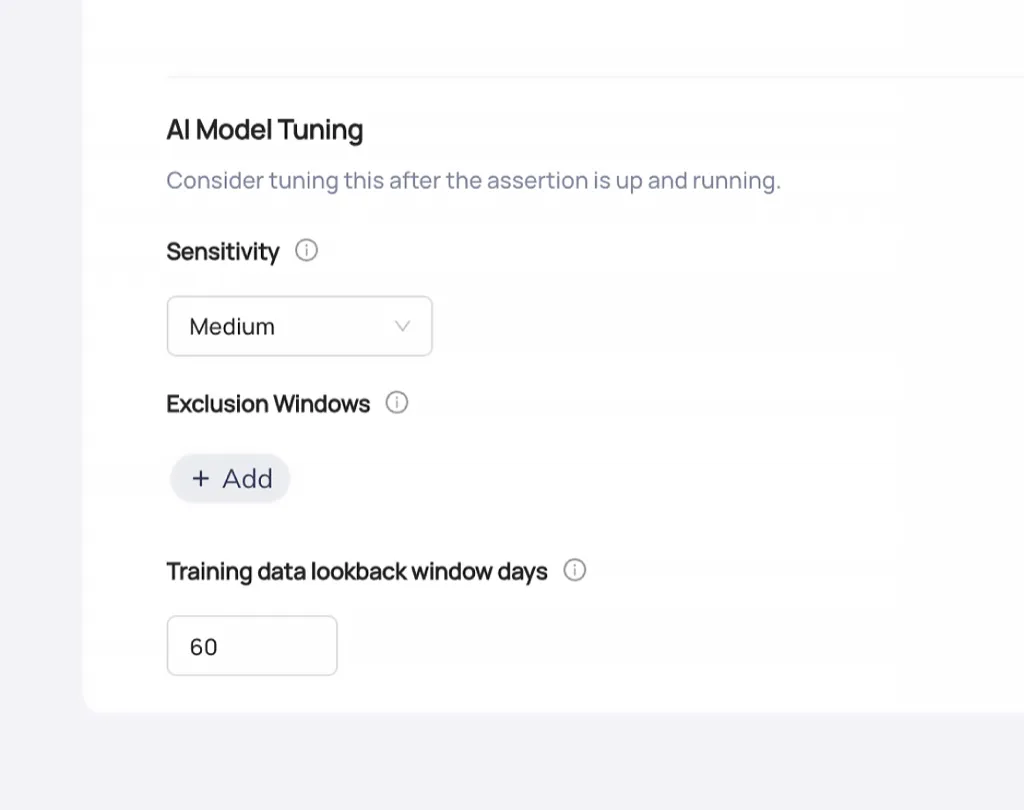
Detect anomalies with AI
ML-powered anomaly detection spots unexpected patterns in data volume, distribution, and quality metrics. Machine learning models identify issues that rule-based checks miss.
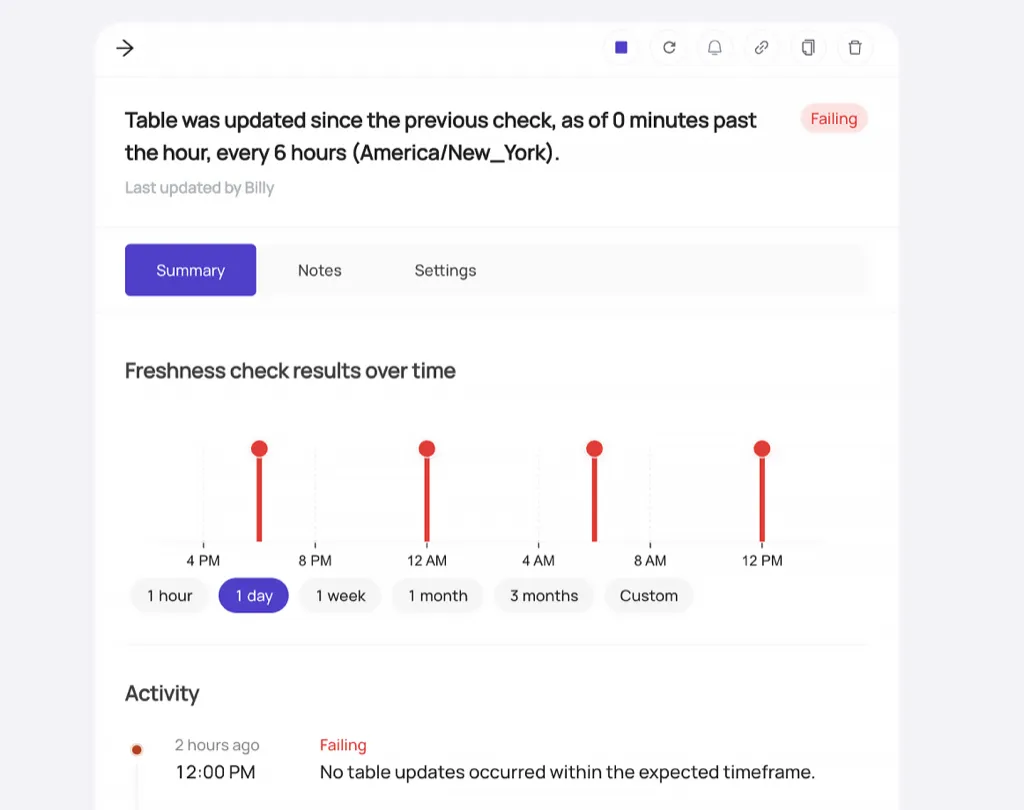
Track incidents from detection to resolution
Built-in workflows manage incidents end-to-end. Historical patterns, schema changes, and quality trends surface root causes in minutes instead of hours of investigation.
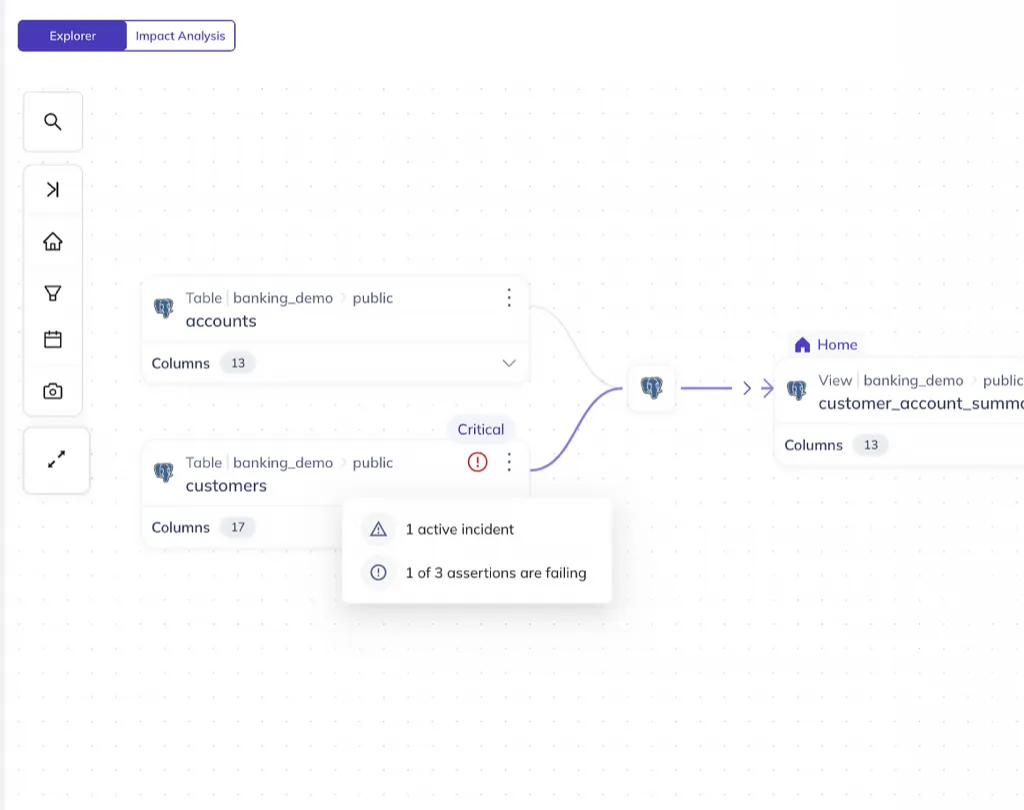
Know what breaks when upstream data changes
Column-level lineage traces data flow from source to dashboard. Blast radius analysis shows exactly which models, reports, and teams are affected the moment upstream data shifts.
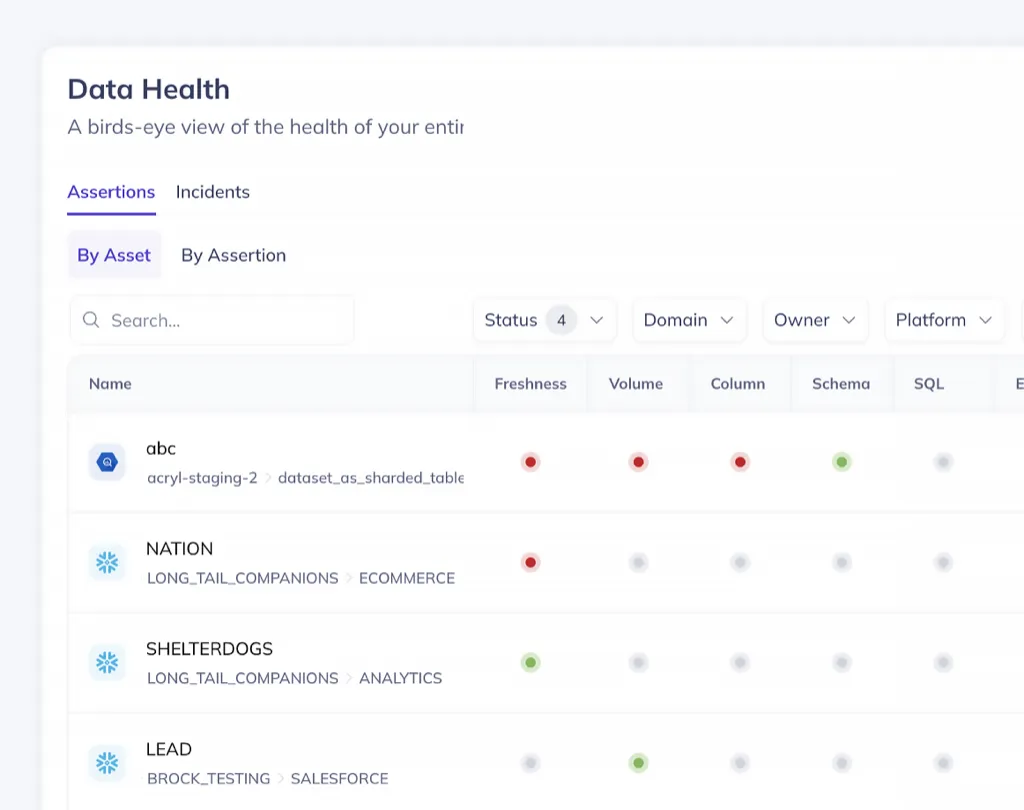
See data health scores across your entire stack
Quality scores show freshness, completeness, and accuracy for every table at a glance. Track SLA compliance and prioritize datasets that need attention without manual status checks.
How teams use DataHub to eliminate data incidents

Data analysts can trust dashboards without data team verification
Freshness monitors and certification badges identify which datasets are production-ready without engineer verification.
Data engineers reduce breaking changes from weekly to zero
See downstream impact across the entire pipeline. Alerts notify affected teams before changes merge so you coordinate proactively.


Data scientists verify data provenance in seconds, not hours
Column-level lineage connects model and feature pipelines to source data so data scientists verify provenance and track transformation.
Real data observability results from enterprise teams
MYOB eliminates breaking changes

“Before bringing DataHub on board, our data teams would see multiple breaking changes per week. Since integrating DataHub into our workflow … DataHub has helped us significantly reduce the number of breaking changes, to the extent that they are no longer a burden on all teams.”
ASAD NAVEED
Engineering Manager, MYOB
CHALLENGE
Managing complex dependency trees across thousands of transformations caused multiple breaking changes per week.
SOLUTION
Implemented DataHub to provide critical data observability insights and automatically notify downstream data consumers before changes merge.
IMPACT
Eliminated breaking changes, reducing incidents from multiple per week to zero.
Built to meet enterprise observability requirements
Proactive monitoring and ML-powered detection
Enterprise performance
Security and extensibility
Ready to turn reactive firefighting into proactive monitoring?
Reactive troubleshooting doesn’t have to be your default.
DataHub Cloud delivers automated monitoring and instant impact analysis that prevent breaking changes before they reach production.


