Data Discovery Platform for Instant Answers
Your teams shouldn’t spend hours searching for data. DataHub Cloud delivers instant answers through AI-powered search—no more hunting through Slack threads or tracking down engineers. Smart recommendations surface trusted datasets so your teams spend less time searching and more time shipping.

Look once.
Find everything.
Ask questions, get instant answers
The Ask DataHub chat agent delivers immediate answers to natural language questions about your data—right in DataHub, Slack, or Teams. Business users self-serve insights instead of waiting for engineers to trace problems manually.

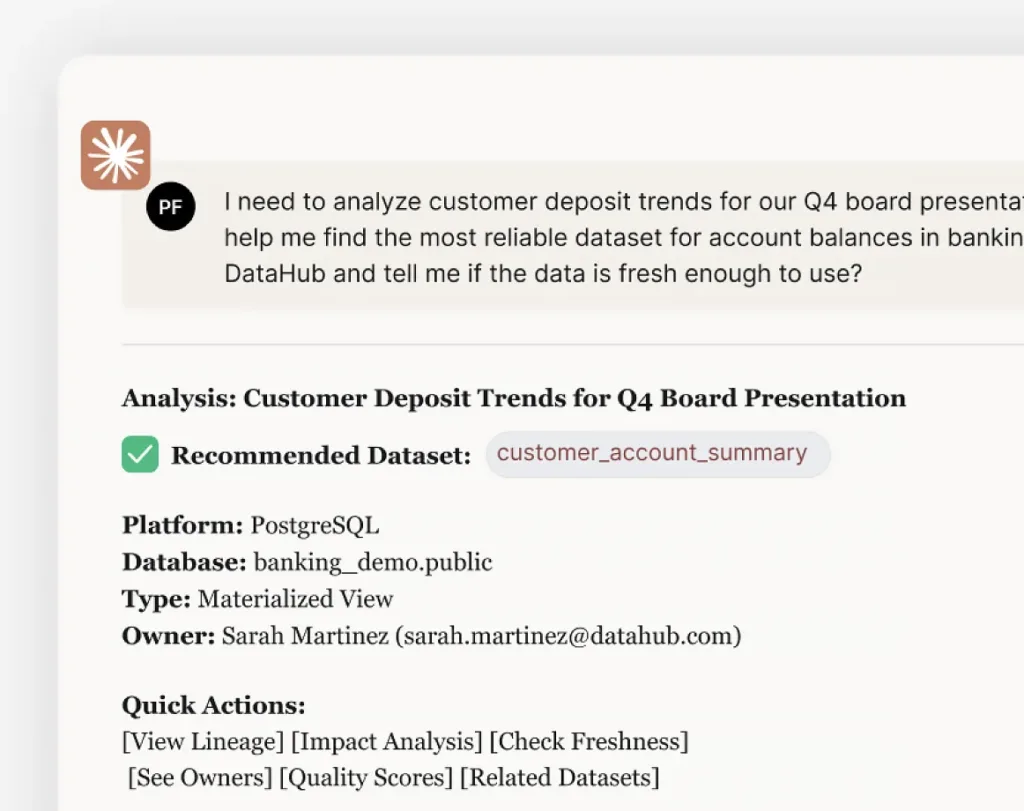
Connect AI agents directly to your data stack
Enable AI tools like Claude, Cursor, and Windsurf to search your data ecosystem with the DataHub MCP Server. AI agents query metadata, traverse lineage, and assess quality programmatically.
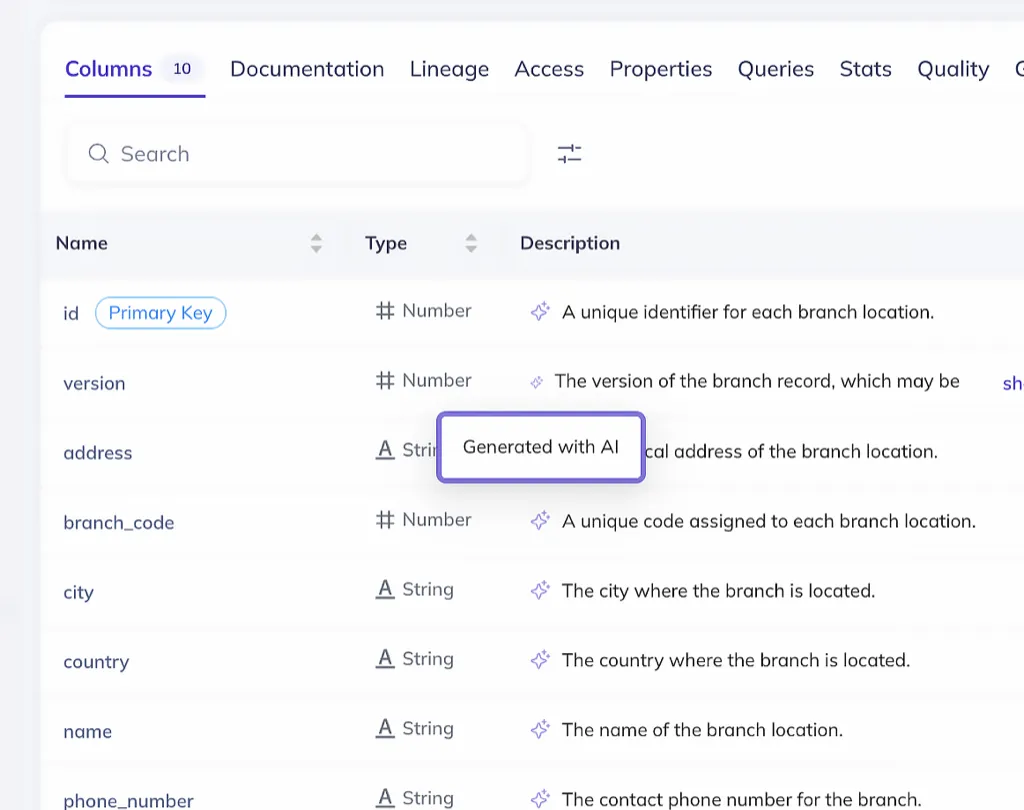
Generate documentation automatically
DataHub AI examines schema, relationships, and usage patterns to generate detailed docs. Then, formats everything to match your custom standards. Plus, you can upload attachments to keep all context in one place.
Surface curated, trusted assets first
Smart ranking ensures teams discover vetted datasets. Data product owners curate collections that guide teams toward production-ready, governed assets.
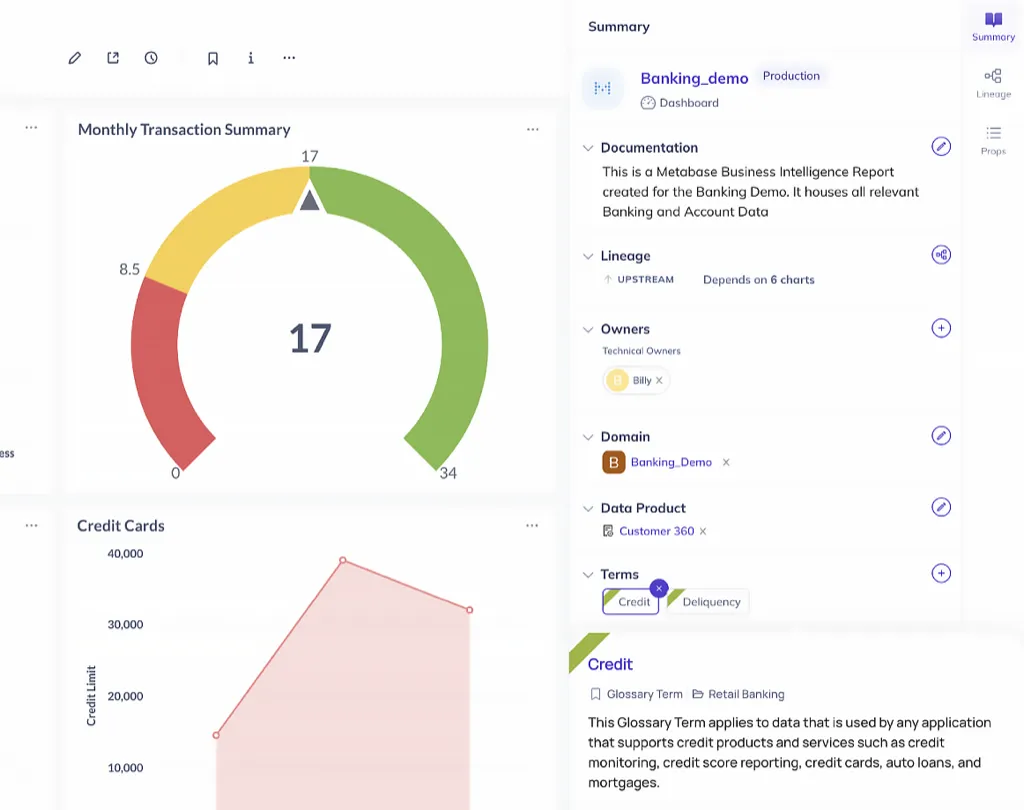
Access data context without leaving your tools
View lineage, data quality scores, and ownership directly in BI platforms through the Chrome extension. Personalized homepage views prioritize your frequently used datasets and role-specific filters for faster discovery.
How teams use DataHub to eliminate discovery bottlenecks

Data analysts ship analysis faster
Discover trusted datasets without guessing table versions. Accelerate analysis and reduce rework from incorrect data sources.
Data engineers identify and eliminate unused datasets
Track which datasets teams actually query and which sit untouched. Confidently deprecate redundant tables and reduce cloud costs.


Data scientists find training data in minutes, not weeks
Find relevant datasets with quality indicators and business context built-in. Solve complex problems faster without bottlenecks.
Real data discovery results from enterprise teams
Notion eliminates data discovery bottlenecks

“We rely on DataHub to gain insights and ensure our critical data is reliable. DataHub’s managed product takes DataHub to the next level through automation and emphasis on time-to-value.”
ADA DRAGINDA
Data Engineer, Notion Labs Inc.
CHALLENGE
Rapid growth led to data complexity with 2,000+ tables across multiple data sources, making it difficult for business users to discover relevant data and distinguish valuable datasets.
SOLUTION
Implemented DataHub as a centralized data catalog to organize, tag, and document all data assets with governance capabilities and data lineage tracking.
IMPACT
Created a “one stop shop” that reduced data noise, shortened new hire onboarding cycles, enabled compliance processes, and prevented breaking changes through impact analysis.
Built to meet enterprise discovery requirements
Discovery where you work
Enterprise performance
Security and extensibility
Ready to turn discovery from bottleneck to breakthrough?
Data discovery doesn’t have to hold up every project.
DataHub Cloud delivers instant, AI-powered data discovery and intelligent recommendations that guide teams to trusted datasets.


