




What is AI Data Management?
Strategies for AI-Ready Data
Quick definition: AI data management
AI data management isn’t just “using AI to catalog data” (though that matters). It’s a dual mandate: AI eliminates metadata busywork so data teams focus on insights instead of documentation toil, while simultaneously treating ML models, features, and LLM apps as first-class citizens alongside traditional data assets.
AI data management involves addressing two complementary challenges:
- Using AI to automate metadata operations—documentation, classification, quality monitoring—that traditionally required armies of data stewards, and
- Managing data assets for AI systems by cataloging models, features, and LLM apps alongside traditional data with the lineage, governance, and observability AI workloads require.
Why now? Traditional data management simply isn’t working at many organizations: The documentation strategy that worked for 50 datasets breaks catastrophically at 500 feature tables that update hourly. Manual metadata stewardship can’t keep pace with AI/ML velocity.
The shift we’re seeing with AI data management is one from passive inventories consulted occasionally to active intelligence layers that participate in every data decision—all operating at machine speed, not human speed.
AI workloads expose what was always true but manageable at smaller scale: Manual tagging, static quality rules, and periodic metadata scans don’t work when data evolves continuously. But now, we’ve also added AI-specific complexity (feature stores, model lineage, LLM training data, embedding pipelines). Traditional catalogs have become documentation graveyards.
The dual mandate: What AI data management actually means
Most vendors conflate “AI-powered catalogs” with “AI data management.” They’re not the same. One uses AI as a feature add-on. The other recognizes AI has fundamentally changed both how we manage metadata and what metadata we need to manage.
1. Using AI to automate metadata operations
Here’s the dirty secret of traditional data catalogs: They fail not because the technology is bad, but because maintaining them is unsustainable:
- Documentation goes stale within weeks
- Glossary terms drift from reality
- Quality rules break when data patterns shift
Teams start ignoring the catalog because it’s faster to ping someone on Slack.
This isn’t a people problem. It’s an architecture problem. Manual metadata management doesn’t scale when you’re cataloging thousands of assets that change daily across hundreds of systems.
Manual metadata management doesn’t scale when you’re cataloging millions of assets across hundreds of systems. AI-powered classification, automated documentation generation, and intelligent anomaly detection aren’t nice-to-have features. They’re the only way to maintain metadata quality at enterprise scale without an army of data stewards.
AI automation addresses the specific toil patterns that cause catalog abandonment:
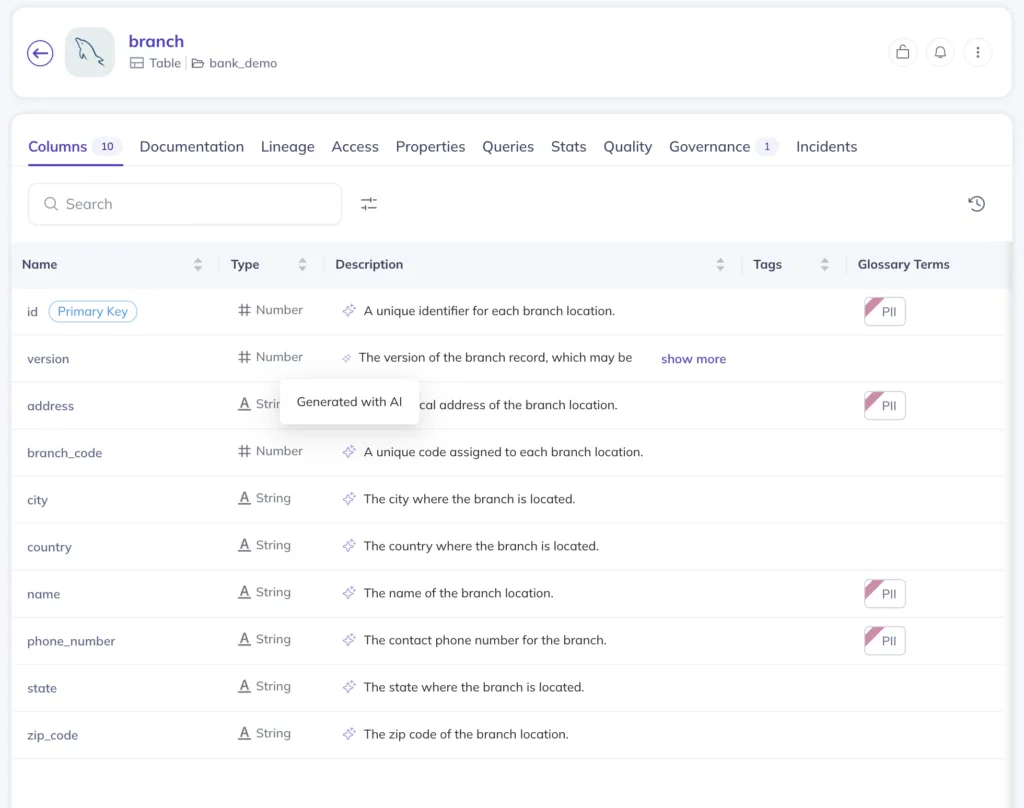
- Documentation generation: Auto-generate descriptions for tables and columns by using natural language processing to analyze schemas, sample values, lineage relationships, and transformation logic. What used to take hours per dataset happens in seconds and stays current as data evolves.
- Automated classification: AI detects sensitive data types (PII, financial information, health records) without manual review of every column. When new datasets appear, classification happens automatically before anyone queries them.
- ML-powered quality monitoring: Instead of manually defining thresholds that break when data patterns shift, machine learning algorithms learn historical patterns (seasonality, trends, statistical complexity) and adapt to “new normal” scenarios. This is literally AI managing data quality for AI systems.
- Real-time orchestration: When metadata changes (tag added, schema updated), trigger workflows automatically: Slack notifications, access control updates, metadata sync across platforms. Real-time governance workflows—no manual coordination required.
Using DataHub, HashiCorp reduced ad hoc data inquiries from dozens daily to 0-1 per day. The difference wasn’t better people; it was automation that eliminated the burden of keeping metadata current.
Similarly, organizations are seeing AI-powered interfaces transform how teams access metadata. Chime found that Ask DataHub “immediately lowered the friction to getting answers from our data. People ask more questions, learn more on their own, and jump in to help each other. It’s become a driver of adoption and collaboration.”
2. Managing data assets for AI systems
Traditional catalogs were designed for data analysis workflows: Help analysts find tables, understand schemas, write queries. AI/ML workloads need fundamentally different context.
But here’s the disconnect: When ML engineers are trying to put models into production, they’re not asking “where’s the customer table?” They’re asking questions like:
- Which datasets trained which machine learning models, and what was model performance?
- What’s the lineage from this raw data through feature engineering to model predictions?
- If I change this feature table, which production models break?
- Has this training data been validated against compliance requirements?
- What transformations were applied, and do they introduce bias?
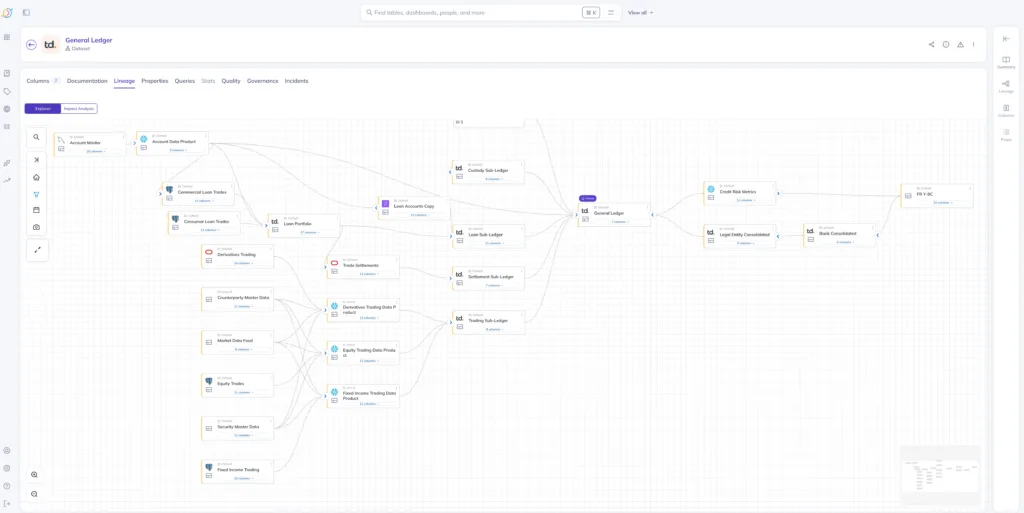
Traditional catalogs can’t answer these questions because they don’t catalog AI assets. They track tables and dashboards. They don’t track ML models, feature definitions, training datasets, LLM pipelines, vector databases, or the lineage connecting everything.
Unified data + AI context really means:
- Cataloging the full AI ecosystem as first-class citizens (models, features, prompts, agents, embeddings, vector stores)
- Maintaining critical relationships and temporal context (which data version trained which model version, what quality metrics existed at that exact time)
- Cross-platform lineage that spans the full AI supply chain (source data → feature engineering → model training → model serving → downstream applications)
- Version history tracking for reproducibility and audit compliance
Here’s a real life case of this in action: Apple uses DataHub as foundation for managing metadata across an evolving ML lifecycle. The platform doesn’t just catalog their ML models—it tracks the complete lineage and context those models need. Learn more about how ML and AI practitioners user DataHub Cloud.
Why both mandates matter
Here’s why both mandates matter and why you can’t solve one without the other: You can’t build production AI if your teams are drowning in documentation toil. When data scientists spend 60% of their time hunting down metadata instead of building models, AI initiatives stall regardless of how sophisticated your ML infrastructure is. The toil problem has to be solved first.
But automation alone isn’t enough. You also can’t govern AI without unified visibility into the full data → model pipeline. Legacy vendors bolt AI features onto catalog architectures that were designed for SQL discovery, not ML operations. Modern platforms architect every capability—search, quality, developer integrations, governance—for AI-first operations from the ground up.
That architectural difference determines whether AI stays in pilots or reaches production at scale.
Why traditional data management can’t support AI at scale
We’ve written extensively about why Gen 2 data catalogs fail at enterprise scale, particularly for AI workloads in our blog post “What Is a Data Catalog?”
But it’s worth highlighting the specific failure modes that make AI data management necessary:
Built for batch, breaking under real-time
Most traditional catalogs ingest metadata on schedules like nightly or weekly. This worked when data warehouses updated overnight. It fails when feature stores update continuously, models retrain hourly, or streaming platforms process millions of events per second. By the time the catalog reflects reality, reality has changed.
Designed for SQL discovery, failing for ML context
Legacy catalogs excel at helping analysts find tables to query. They struggle with everything AI systems need: Lineage connecting training datasets through feature engineering, model performance tracked against data quality, transformations that might introduce bias, validation against AI readiness criteria.
Static rules that break when data evolves
Traditional quality monitoring operates on manual thresholds: Volume must exceed X records, freshness must be under Y hours. These rigid rules work fine for stable batch workflows. They break catastrophically for ML training data where distributions shift seasonally, feature values are non-stationary, and usage patterns change as models evolve. Teams end up spending more time tuning brittle rules and performing manual data cleansing than investigating actual data quality issues.
What’s needed instead: ML-powered monitors that learn historical patterns and adapt as data evolves, not static thresholds that become obsolete within weeks.
Fragmented tools, missing context
Most organizations handle data discovery, governance, and observability as separate concerns requiring separate tools. You search for data in the catalog, check quality in your observability platform, verify compliance in your governance tool.
Each system maintains its own metadata, its own lineage graph, its own understanding of what data means, creating data silos that prevent holistic governance. When a quality issue impacts a compliance-critical ML model, no single system connects those dots. Teams waste hours manually tracing dependencies across fragmented tools—and still miss the full picture because context doesn’t flow between systems.
The fragmentation across discovery, governance, and observability tools isn’t just inconvenient—it’s architecturally incompatible with AI operations. Context-aware governance is impossible when lineage lives in one system, quality metrics in another, and business definitions in a third.
Who actually needs AI data management
Not every organization needs enterprise-grade AI data management immediately. Spreadsheets and Slack can serve small teams effectively at early stages of operation. But specific inflection points signal when basic approaches become bottlenecks.
Here’s the thing: Waiting too long often means scrambling to retrofit governance when regulators or boards start asking hard questions.
Scale and complexity triggers
You’ve crossed the threshold when:
- Multiple teams independently build pipelines without central coordination
- Incidents regularly require hours or days to trace through data dependencies
- Storage costs are significant but no one knows which data can be safely deprecated
- New team member onboarding takes weeks because internal knowledge isn’t documented
AI and ML deployment triggers
The AI imperative appears when:
- Board mandates exist for putting artificial intelligence in production, not just running pilots
- ML projects stall because teams can’t validate training data compliance
- Models can’t move to production due to lineage and provenance questions
- Data science teams spend more time hunting for feature tables than building models
- You need to answer “what data trained this model?” for regulatory compliance
- Feature engineering happens in silos without shared feature stores or discovery
Organizations operating at massive scale with sophisticated AI operations, like Apple and Netflix have adopted DataHub specifically because traditional catalogs couldn’t handle the metadata complexity AI workloads create.
Compliance and governance triggers
Regulatory requirements drive urgency when:
- You operate in regulated industries requiring audit trails (finance, healthcare, government)
- GDPR, CCPA, or similar regulations demand precise visibility into sensitive data flow
- Column-level lineage is required to prove PII handling, not table-level approximations
- AI regulations (EU AI Act, emerging frameworks) require demonstrating data provenance for high-risk AI systems
- SOC 2, ISO 27001, or other certifications require metadata access controls, data security protocols, and audit logs
Organizational readiness signals
Cultural indicators that you’re ready:
- Executive sponsorship exists for treating data management as strategic infrastructure, not IT overhead
- Business stakeholders demand self-service access to analyze data and won’t tolerate ticket queues
- Data engineers spend more time answering “where is this data?” than building
- Leadership recognizes that governance scales through automation, not headcount
- You’re willing to empower data stewards with organizational authority, not just catalog access
Organizations often wait too long to implement enterprise data catalogs, doing so reactively after incidents, failed audits, or board pressure. Here’s the pattern we too often see at DataHub: Companies invest in basic tooling early, hit scale/AI limitations within 18-24 months, then face painful migrations to platforms that could have handled their growth trajectory from the start.
Choosing architecture designed for where you’re heading beats optimizing for today’s constraints and migrating in three years.
Is your current approach to data management future-proof?
The capabilities we’re discussing may seem advanced today, but they’re fast becoming requirements. The question is whether your current architecture can evolve to support where data operations are heading.
Ask yourself these questions about your current approach:
Can your platform support autonomous AI agents?
AI agents are already handling routine data tasks in production environments—discovering datasets, validating compliance, checking quality thresholds, executing transformations. Within two years, most enterprises will run hundreds of agents operating with minimal human oversight.
Your metadata platform either enables this or blocks it. Ask yourself:
- Can AI agents query metadata programmatically to make decisions?
- Can they validate governance requirements before acting?
- Can they record their actions for audit trails?
- Do your APIs provide the context agents need, or are they designed exclusively for human interfaces?
Block pairs DataHub’s MCP Server with their AI Agent Goose to accelerate incident response.
“Something that might have taken hours, days, or weeks turns into just a few simple conversation messages.”
Sam OsbornSenior Software Engineer, Block
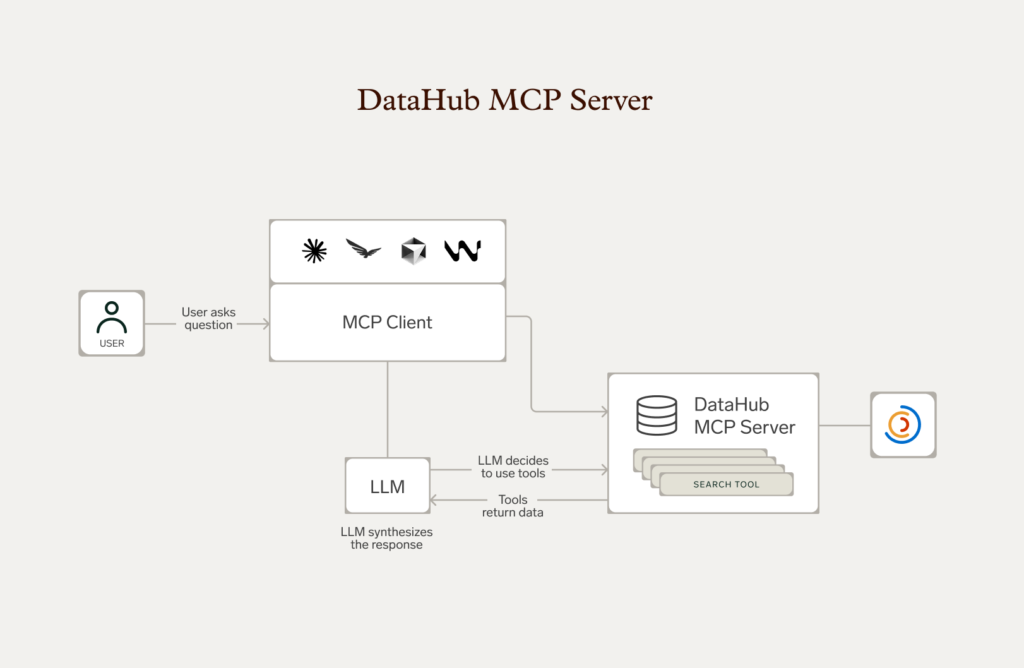
Event-driven architectures and comprehensive APIs designed for machine consumption—not human UIs with APIs bolted on—separate platforms that will scale from those that won’t.
Can you scale to trillions of metadata events?
Current platforms handle billions of records and thousands of users. The next generation must process trillions of metadata events generated by streaming platforms, real-time pipelines, and autonomous agents making continuous decisions.
The architectural patterns enabling this scale (event-driven processing, disaggregated storage, efficient graph queries) aren’t features you can tack on later. They’re foundational design decisions.
If your metadata platform runs scheduled scans rather than processing events in real-time, you’re already seeing the constraints. That gap will only widen as metadata velocity increases alongside data velocity.
Will your architecture survive the next platform shift?
Data architectures change faster than metadata platforms. The lakehouse you’re building today must integrate with both existing data systems and platforms that don’t exist yet like new vector databases, embedding stores, and AI orchestration frameworks. Emerging standards like Model Context Protocol (MCP) will define how AI systems interact with metadata.
Proprietary metadata formats and closed ecosystems become anchors when the data landscape shifts. Open-source foundations, extensible metadata models, and standards-based integration determine whether you adapt quickly or face disruptive migration.
DataHub’s open-source architecture with 14,000+ community members means the platform evolves with industry standards rather than vendor roadmaps. Custom extensions remain compatible because they use the same mechanisms the community relies on.
Can you avoid the next migration?
Migrating metadata platforms is extraordinarily difficult. Unlike swapping BI tools where visualizations can be recreated, metadata embeds deeply into operational workflows, governance processes, and organizational practices.
The lineage graphs, business glossaries, data models, quality definitions, and ownership models you build represent significant organizational investment that doesn’t transfer easily between platforms.
Traditional catalogs and modern platforms may look similar in demos focused on search and discovery. The difference appears when you need real-time lineage for production AI, comprehensive APIs for agent integration, or flexible metadata models for emerging use cases—requirements that seem optional today but become blockers tomorrow.
Choose a platform without these capabilities, and you’ll face either a costly migration in three years or constraints that limit your AI ambitions. Choose architecture designed for requirements you don’t have yet, and you build foundation instead of technical debt.
Evaluating AI data management platforms: What really matters
When you sit through AI data management demos, they all showcase similar features: Search, lineage, quality monitoring, integrations. The differences that matter only emerge when you probe architectural decisions and understand where your organization is heading, not just where it is today.
The evaluation mistake most teams make: Comparing feature checklists (“Does it have lineage? ✓ Does it have quality monitoring? ✓”) misses what matters. The questions that predict long-term success:
- Can this architecture scale with our AI ambitions?
- Will it support autonomous operations as agents proliferate?
- Does the platform adapt to emerging standards (like MCP), or lock us into proprietary interfaces?
Choose wrong, and you’re either planning a painful migration in three years or accepting constraints that kill your AI roadmap. Choose right, and you’re building on architecture that grows with your needs.
Here’s what really matters, and the questions to ask, instead:
1. Architecture: Real-time vs. batch processing
Why it matters: Batch metadata collection (nightly scans, weekly updates) creates gaps where metadata lags reality. This breaks automated workflows, governance policies that need to evaluate new assets immediately, and incident response that requires current lineage.
Questions to ask:
- How quickly do metadata changes appear in the catalog? Hours? Minutes? Seconds?
- Is the platform event-driven (streaming metadata via Kafka) or batch-oriented (scheduled scans)?
- Can governance policies evaluate new datasets before anyone queries them, or only after discovery?
- When schemas change or incidents fire, does the catalog reflect it in real-time?
2. Coverage: Data-only vs. unified data + AI
Why it matters: Traditional catalogs handle tables, views, dashboards. They don’t track ML models, feature definitions, training datasets, LLM pipelines, vector databases, or the lineage connecting everything. If you’re building production AI, fragmented visibility between data and ML systems creates governance gaps.
Questions to ask:
- Can you catalog ML models, features, prompts, agents, embeddings as first-class assets?
- Does lineage trace from raw data through feature engineering to model predictions to downstream applications?
- Can you track which data version trained which model version for reproducibility and compliance?
- Is there unified governance (one set of policies, one access control model) across data and AI assets?
3. Visibility: Column-level vs. table-level lineage
Why it matters: GDPR, CCPA, and AI regulations require knowing exactly which columns contain PII and exactly where those fields flow, not just approximations. Table-level lineage tells you that Table A feeds Table B. Column-level lineage tells you which specific fields flow through which transformations—critical for compliance and impact analysis.
Questions to ask:
- Can you trace a specific column (e.g., customer_email) through all transformations to all downstream consumers?
- Does lineage capture column-level dependencies from transformation logic (SQL, dbt, Spark)?
- When you need to change a sensitive field, can the platform show exactly what breaks?
4. Integration: UI-centric vs. API-first design
Why it matters: Platforms designed for human UIs with APIs bolted on can’t support autonomous agents, automated validation, or CI/CD integration at scale. API-first architectures treat programmatic access as a primary design goal, not an afterthought.
Questions to ask:
- Were APIs designed for machine consumption from the ground up, or added to satisfy checkboxes?
- Can AI agents query metadata, validate compliance, and record actions without hitting rate limits?
- Do CI/CD pipelines have the API access needed to check lineage before deployments?
- Are there examples of customers using APIs for agent workflows, not just human-triggered scripts?
Beyond API design, integration breadth determines time-to-value:
5. Integration breadth: Pre-built vs. custom development required
Why it matters: Limited connectors mean manual work to catalog critical systems—and those custom data integration projects become technical debt when platforms upgrade. Broad pre-built connector ecosystems reduce time-to-value and ongoing maintenance.
Questions to ask:
- How many pre-built connectors exist for your specific platforms (Snowflake, Databricks, dbt, Airflow, Tableau, etc.)?
- Who maintains connectors—vendor only, or active community contributions?
- What’s the process for new integrations when you adopt new platforms?
- Are there examples of customers cataloging 100+ sources without custom development?
6. Automation: Manual maintenance vs. AI-powered operations
Why it matters: Manual metadata management doesn’t scale. The catalog that requires humans to document every dataset, tag every column, and maintain rules for every quality check becomes stale within weeks, and then teams abandon it for Slack.
Questions to ask:
- Does the platform auto-generate documentation, or rely on humans to write descriptions?
- Is classification automated through AI detection, or manual tagging workflows?
- Do quality monitors learn data patterns and adapt (ML-powered), or require manual threshold definition?
- Can metadata propagate through lineage automatically, or does every downstream asset need separate documentation?
7. Governance: Unified vs. fragmented architecture
Why it matters: Separate tools for discovery, data governance, and observability create gaps in visibility. When quality issues impact compliance-critical dashboards, you need a single system that connects quality → lineage → governance impact automatically, not fragmented tools that require manual correlation.
Questions to ask:
- Is there a single metadata graph connecting discovery, quality, governance, lineage—or multiple tools?
- Can you see data quality metrics and compliance status directly in search results, or context-switch between tools?
- When incidents occur, does the platform automatically correlate quality → lineage → governance impact?
8. Ecosystem: Proprietary vs. open-source foundation
Why it matters: Vendor lock-in creates migration risk when your needs diverge from roadmap priorities. Open-source foundations ensure the platform evolves with industry standards, not just vendor interests, and give you an exit path if needed.
Questions to ask:
- Is there an open-source core, or purely proprietary?
- How large is the community? (Thousands of contributors signal ecosystem health vs. vendor-only development)
- Can you self-host if needed, or are you locked into SaaS-only?
- Do major enterprises (LinkedIn, Netflix, Apple) run the platform in production at scale?
Implementing AI data management: What separates success from stalled pilots
Technology can’t fix organizations that fundamentally don’t value documentation or governance. If leadership treats metadata as overhead, if teams are rewarded for shipping features but not maintaining quality, if governance is viewed as bureaucratic friction rather than enabling infrastructure, no catalog will succeed.
The platform creates capability. Organizational commitment determines whether that capability gets used. Successful deployments follow patterns that respect organizational reality rather than idealized rollout plans.
Start with high-value use cases, not comprehensive coverage
The impulse to catalog everything before declaring success kills momentum. Instead, identify specific pain points where better metadata delivers immediate, measurable value:
- Accelerating incident response through automated lineage: When pipelines break at 3am, engineers need to trace root cause in minutes to restore high-quality data flows, not spend hours on manual investigation. Comprehensive lineage (captured automatically, updated in real-time) turns diagnosis that used to take half a day into 15-minute fixes. This use case typically resonates with data engineering leadership who feel incident pain acutely.
- Enabling self-service data analytics for a specific business unit: Choose a team that’s motivated (marketing analytics, finance reporting) and implement thorough metadata coverage for their domain. Well-documented datasets with strong business context let them find and understand data independently, reducing ticket queues and enabling the data team to focus on higher-value work.
- Establishing AI readiness for production ML deployment: Organizations with board mandates to put models in production but struggling with lineage validation, compliance documentation, or reproducibility challenges need unified data + AI visibility. Solving this bottleneck typically unblocks multiple stalled AI initiatives simultaneously.
Each use case builds capability for the next. Lineage captured for incident response serves AI readiness. Business glossaries created for self-service enable better governance. Start narrow, prove value, expand deliberately.
Executive sponsorship + empowered data stewards
Metadata management fails when treated as a tool rollout rather than organizational change. Two factors predict success more reliably than any technical consideration:
- Executive sponsorship establishes metadata management as strategic infrastructure, not IT overhead. This means:
- Budgets that survive quarterly scrutiny and competing priorities
- Mandates that drive adoption across business units, not just data teams
- Visible leadership commitment that signals “this matters” to the organization
- Authority to enforce documentation and governance standards
- Empowered data stewards own business metadata and have organizational authority to enforce standards. Platforms don’t magically populate themselves with accurate business context. Someone must define glossary terms, certify datasets, identify critical data elements, establish ownership, maintain quality standards.
The platform can automate technical metadata capture and AI can assist with classification, but business meaning and governance policy still require human judgment backed by organizational authority. Stewards without authority create documentation no one respects. Authority without platform capabilities means manual work that doesn’t scale.
“The biggest implementation mistake is treating metadata management as a technical project when it’s fundamentally an organizational one. Technology enables the transformation, but executive sponsorship and empowered data stewards determine whether you actually achieve it.”
John JoyceCo-Founder, DataHub
Metrics that matter, not vanity metrics
Avoid measuring activity (“number of assets cataloged,” “percentage of tables documented”). Instead, focus on outcomes that reflect business value:
- Time-to-trust: How long does it take a data consumer to go from discovering a dataset to confidently using it in production? Strong metadata management should compress this from days to hours—or hours to minutes—by surfacing quality metrics, lineage, business context, and ownership immediately.
- Incident resolution speed: Mean time to resolution for data quality issues and pipeline failures should decrease dramatically. If lineage is comprehensive and current, root cause analysis happens in minutes instead of the multi-hour archaeology expeditions common with fragmented tools.
- AI deployment velocity: Track time from model development to production deployment. Metadata management should reduce this through automated compliance validation (is this training data approved for use?), lineage verification (can we reproduce results?), and governance checks (do we have the right approvals?).
- Reduction in manual metadata work: Measure time data teams spend on documentation, classification, and answering “where is this data?” questions. Automation should free capacity for higher-value work—feature development, data cleaning and quality improvement, strategic initiatives.
- Self-service adoption: Percentage of data requests resolved without data team involvement. As metadata quality improves and self-service tools mature, business stakeholders should find and trust data independently.
Ready to see AI data management in action?
The gap between traditional data management and AI-native platforms isn’t about features—it’s about architectural foundations. If your current approach is struggling to keep pace with AI initiatives, real-time data operations, or autonomous agent workflows, it’s worth exploring what’s possible with infrastructure built for where data management is heading.

