Context Management Is the Missing Piece in the Agentic AI Puzzle
Context Management Is the Missing Piece in the Agentic AI Puzzle
By Shirshanka Das, Co-Founder and CTO of DataHub | November 7, 2025
Imagine you’re a sales engineer. It’s Monday morning, and your CRO storms in with urgent news: Southeast sales have dropped 20%, and the board meeting is in 48 hours.
What follows is a familiar nightmare for anyone working with data:
- Discovery chaos: 50 Slack messages later, you’re drowning in outdated wikis and five datasets all named “sales_final_v2″—none with the right region field.
- Access gridlock: IT tickets pile up. Approval delays stretch. Wrong permissions block critical data. Compliance issues surface.
- Quality concerns: When you finally get access, the data has quality issues that require an all-nighter to resolve.
- The result: 42 hours on discovery and access, 6 hours on actual analysis, and you’re still no closer to understanding why sales dropped.
Now imagine this scenario multiplied by a thousand AI agents working simultaneously at machine speed, each one hitting the same obstacles (fragmentation, access controls, quality issues) but now at scale. And here’s the twist that makes it worse: AI agents love to agree with us, often confirming our biases and telling us we’re exactly right (even when we’re not).
We’re combining all the problems humans encounter working with data, plus the unique challenges of AI.
That’s why so many agentic AI initiatives never hit production—and why the ones that do often fail to deliver expected value. In fact, Gartner predicts that by 2027 almost half of agentic AI projects will be canceled.
The solution: Context management
The answer isn’t more sophisticated models or better prompt engineering. We need a new approach. One that addresses the foundational infrastructure AI agents need to work reliably at enterprise scale.
At DataHub, we’ve coined the term “context management” to describe this emerging category. We’re introducing this framework because the industry needs language to talk about what’s missing: the systematic, organization-wide approach to delivering reliable context that goes beyond point solutions and individual applications.
We’re not the first to see that agents need better context. But we are the first to recognize that the solution isn’t better context engineering within each application. It’s context management across the enterprise.
What is context management?
Context management is the organization-wide capability to reliably deliver the most relevant data to AI context windows, enabling the governed and enterprise-scale deployment of agents.
It’s context engineering applied systematically across your entire organization, not just within individual applications.
The three Rs: What makes context work
If models could speak (and increasingly, they sort of can), they’d tell us they need three things from context:
1. Relevance
Context must be timely and domain-appropriate. Last year’s data won’t help with today’s crisis. Agents need semantic search capabilities to find what matters for the task at hand, not just what exists.
2. Reliability
Context must be trustworthy with clear provenance. Where did this insight come from? Can I verify its lineage? This becomes critical for agent-to-agent handoffs and audit requirements. When an agent makes a business decision, you need to trace it back to authoritative sources.
3. Retention
Context must persist across conversations and invocations. Agents need to learn from past experiences, building institutional knowledge over time. Without retention, every interaction starts from zero, which means wasted resources and missed patterns.
Traditional context engineering delivers these capabilities within individual applications. Context management delivers them across your entire enterprise.
At DataHub, we define context management as an organization-wide capability to reliably deliver the most relevant data to AI context windows, enabling the governed and enterprise scale deployment of agents.
Why context management matters now (and why it’s urgent)
To understand why context management is critical, let’s trace how we got here and where each approach hits its limits.
Prompt engineering: The single-shot era
Prompt engineering taught us to ask questions precisely, provide good examples, and format responses carefully. It worked for one-off queries but broke down when tasks required large knowledge bases or multiple steps. You simply can’t fit your entire customer database or product catalog into a single prompt, no matter how large your context window gets.
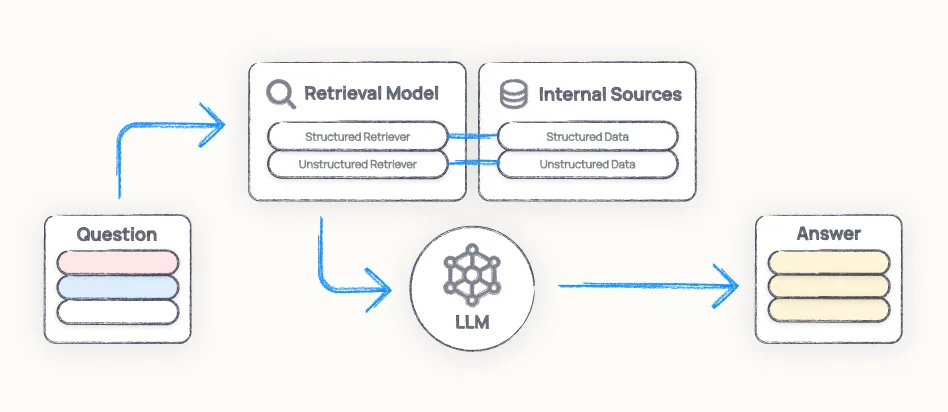
RAG (retrieval-augmented generation): The search solution
RAG was a breakthrough. Using embeddings and semantic search, we could pull relevant context from large knowledge bases without overwhelming the model. But RAG is inherently reactive and application-specific. Each team builds their own RAG pipeline, choosing their own vector database, embedding model, and retrieval strategy. There’s no consistency, no shared understanding of what’s reliable.
Context engineering: The toolkit without the manual
Context engineering brought together memory, tool calling, structured outputs, guardrails, and sophisticated prompt management into a cohesive toolkit. It’s powerful, but it leaves the most critical questions unanswered:
- Where does this context come from?
- How do I know it’s trustworthy?
- How do I ensure consistency across applications?
- How do I govern access at scale?
Context engineering gives you the LEGO blocks to fill a context window. It doesn’t tell you which blocks to use, where to find them, or whether they’re safe to build with.

Context engineering vs. context management: The critical difference
You’re probably wondering, what’s the difference between context engineering and context management?
Context engineering solves the problem within a single application. It’s the techniques and tools one team uses to fill their agent’s context window effectively. It ends up being artisanal, bespoke, and isn’t well set up to scale across an organization.

Context management is what gives it those superpowers by solving this across your entire enterprise. It’s the organizational capability that ensures every agent (regardless of which team built it) can reliably discover, trust, and use context. It’s systematic, governed, and built for scale.

Think of it this way: Context engineering is like each development team writing their own authentication system. Context management is like implementing enterprise SSO. Both get you logged in, but only one is maintainable when you have hundreds of applications.
Context engineering solves the context problem within applications. Context management solves it across your entire enterprise.
Why enterprises need context management
We’re in the middle of an AI gold rush. A recent survey from Google Cloud found that more than half (52%) of enterprises are actively using AI agents, with 39% reporting their company has launched more than ten. But is all of this frantic activity leading to productive outcomes?
- Fragmentation at scale: Each team is building bespoke context engineering solutions. One team uses Pinecone for embeddings. Another uses Weaviate. A third team built their own vector database. Your customer-facing agent and your internal agent aren’t using the same knowledge base, so they’re giving different answers to the same questions.
- The microservices lesson we forgot: Remember when Uber ended up with five times as many microservices as engineers? They eventually had to pull back and establish central standards to maintain sanity. We’re watching the same pattern emerge with AI, but we’re moving much faster this time.
- Compliance nightmares ahead: As agents gain autonomy to make decisions and take actions, regulatory scrutiny will intensify. Just under two-thirds (60%) of AI leaders cite risk and compliance concerns as one of the top barriers to adopting agentic AI. Without standardized context management, you’ll struggle to audit what agents did or why they did it, especially when operating at enterprise scale.
- The trust crisis: What’s at stake isn’t just inefficiency—it’s trust. When agents make decisions based on unreliable context, when they can’t explain their reasoning, when they duplicate work or contradict each other, organizations will stop delegating meaningful work to them.
The real risk isn’t that AI will fail. It’s that we’ll lose trust before AI gets a chance to succeed.
How DataHub powers context management for AI agents
At DataHub, we’ve been building the foundation for context management from day one.
DataHub architecture enables context management
As a metadata platform built on an event-sourced architecture, DataHub already delivers the core capabilities AI agents need:
Knowledge graph foundation
Our metadata graph connects datasets, columns, dashboards, ML models, business glossaries with metrics and concepts, people, and systems through meaningful relationships. It already captures lineage, ownership, documentation, and quality metrics, which make up the contextual intelligence agents need to make informed decisions.
Real-time context visibility
DataHub streams metadata changes in near real-time, ensuring agents always work with fresh, accurate context. When a table schema changes or data quality issues emerge, agents know within seconds.
DataHub MCP Server
Our Model Context Protocol server makes the entire context graph accessible to AI agents through a standard interface. Data teams are already using it to enable AI agents to find and safely use data. Data engineers are investigating issues in seconds, tracing impact across their entire data stack.
DataHub product capabilities already deliver context management fundamentals
DataHub already solves some of the hardest problems in context management:
- Discovery: DataHub indexes all your data and data-adjacent systems (APIs, warehouses, lakes, BI tools, ML features) making context discoverable and easily accessible through natural language queries.
- Lineage: Our column-level lineage capabilities trace every piece of context back to its source, providing the provenance agents need for reliable decision-making.
- Reliability: Data quality monitoring, freshness tracking, and usage analytics ensure agents work with accurate, up-to-date context.
- Governance: DataHub’s automated governance workflows operationalize policies so the right people (and systems) have the right access at the right time.
Our vision: Transforming enterprise data into context
We’re defining context management and building the platform to deliver it.
Having spent ten years building metadata infrastructure at LinkedIn and now watching AI initiatives at the world’s most advanced technology companies, we’ve been the first to see where this is heading—and the chaos that’s coming if enterprises don’t get ahead of it.
While others are focused on building better agents, we’re focused on building the infrastructure that provides agents with the trusted context that they need.
We’re committed to evolving DataHub to set the standard for the context management category. Our roadmap is driven by the problems we’ve seen firsthand as organizations deploy agents in production: fragmented context sources, inconsistent reliability, governance gaps, and the inability to scale beyond pilot projects.
This isn’t about adding vanity AI features. It’s about fundamentally reimagining how enterprises deliver context to AI systems with the same rigor, governance, and scalability they’ve applied to data management over the past decade.
As the category matures, so will our platform. We’re building alongside our open source community of 14,000+ practitioners who are on the front lines of agent deployment, learning what works and what breaks in production environments.
We’re so excited about what becomes possible when context management is solved:
- A Data Custodian Agent that continuously monitors your data ecosystem, identifies unused assets driving up storage costs, orchestrates approvals from the right stakeholders, and cleans up resources automatically—all while maintaining full audit trails.
- An AI SDR that doesn’t hard-code connections to Salesforce but intelligently discovers your authoritative data source (whether that’s Snowflake, HubSpot, or a hybrid during migration) and uses verified context to engage prospects without damaging your brand.
- An Experience Optimizer that analyzes customer feedback from Zendesk, product telemetry from Mixpanel, and inventory data from your warehouse to identify root causes of user frustration. Then, automatically proposes, tests, and validates product improvements.
Wouldn’t that be amazing? These agents aren’t guessing where to find context or which source to trust. They’re powered by context management infrastructure that understands your enterprise.
How to get started with context management
If you’ve gotten this far, you’re probably ready to move beyond artisanal context engineering! Here’s what you can do today to start building context management capabilities that scale across your organization:
Step 1: Map your context landscape
Before you can manage context, you need to understand where it lives. Conduct an inventory across three dimensions:
- Technical context: Catalog data lineage, schema definitions, quality metrics, version control, and technical dependencies. This helps agents understand how to interpret and process your data.
- Operational context: Map runtime metrics, access patterns, data SLAs, system dependencies, and operational policies. This tells agents which sources to trust and their performance characteristics.
- Business context: Capture the human knowledge and governance frameworks that live in your business glossary, docs, wikis, Slack channels, access control policies, or domain expertise held by specific teams. This tells agents about data’s organizational meaning.
The output: A clear picture of where authoritative context exists and where the gaps are.
Step 2: Identify and prioritize agentic use cases
Not all agentic applications are created equal. Start with use cases that have:
- High-impact business value: What would move the needle if automated? Customer support triage? Data quality remediation? Anomaly investigation?
- Manageable scope: Choose bounded problems with clear success criteria. A data custodian that archives unused tables is more achievable than an agent that rewrites your entire data architecture.
- Available context: Pick use cases where you already have (or can quickly build) the context infrastructure. Don’t start with applications that require context from systems you haven’t cataloged yet.
- Risk tolerance alignment: Balance innovation with governance. Start with internal-facing agents where mistakes are reversible before deploying customer-facing applications.
Create a prioritized roadmap with 2-3 pilot use cases that can demonstrate value quickly.
Step 3: Build your knowledge graph foundation
Here’s where context management becomes real. You need a unified knowledge graph for your enterprise data that connects your technical, operational, and business context into a single queryable system.
This is what DataHub was built for. Our metadata platform ingests metadata from across your stack, captures relationships between datasets and owners, makes context searchable through natural language, and tracks lineage and quality metrics in one place.
See DataHub Cloud in action
Take our interactive product tour to explore how leading enterprises manage data and AI assets at scale.
Step 4: Deploy and measure pilot agents
Launch your prioritized use cases with tight feedback loops:
- Instrument everything: Track which context agents access, how often, and with what outcomes. Measure accuracy, latency, and business impact.
- Start in observation mode: Let agents recommend actions before they take them. Build trust with stakeholders before granting autonomy.
- Create feedback mechanisms: Make it easy for users to flag when agents get things wrong. Use these signals to improve.
- Iterate on context delivery: As you learn what agents actually need, refine your knowledge graph to meet agents where they are.
Step 5: Scale across the organization
Once pilots prove value, expand systematically:
- Standardize patterns: Document what works. Create templates for new agentic applications that inherit governance and context access patterns.
- Build organizational muscle: Train teams on context management principles. Make it part of your AI development culture, not an afterthought.
Organizations that treat context as shared infrastructure will deploy trustworthy agents while others are still fighting fragmentation.
Context management isn’t a one-time project. It’s a capability you build incrementally. Start with inventory, prove value with pilots, then scale systematically.
Ready to build trustworthy AI agents?
The teams that build context management capabilities now will have agents that can truly be trusted with meaningful work. The teams that don’t will have a thousand eager agents giving confident wrong answers.
See DataHub in action: Take our interactive product tour to explore how DataHub Cloud powers context management at scale.
Dive deeper into context management: This post scratches the surface of what I covered in my CONTEXT keynote. Watch the keynote on demand to get the full story.
The future where PMs, engineers, and data practitioners can trust AI to ship great products on their behalf requires a foundation of reliable, discoverable, trustworthy context. That future starts with context management.
Recommended Next Reads



