




Introducing DataHub Cloud v0.3.12
DataHub Cloud v0.3.12 is now live! This update brings powerful enhancements across AI-powered documentation, data source management, managing data quality at scale, finding trustworthy data using natural language, and more.
Let’s take a look at what’s new!
Introducing the DataHub MCP server
This release introduces a fully managed, hosted Model Context Protocol (MCP) server—making DataHub metadata accessible to AI-native tools like Claude Desktop, Cursor, Windsurf, and more.
No setup. No maintenance. Just powerful access to trusted metadata, out of the box.
With the hosted MCP server, AI tools can now search, interpret, and act on your most reliable data assets—enabling better decisions and reducing time spent digging for answers. Here’s what it unlocks:
- Search for data: Ask questions in plain English to find the right datasets for your analysis—without relying on tribal knowledge.
- Dive deeper: Cut through the noise with rich metadata context: usage, ownership, documentation, tags, quality signals, and more.
- Perform impact analysis: See the downstream impact of changes to tables, reports, or dashboards using DataHub’s powerful lineage graph.
- Understand usage patterns: Discover how your most critical data is being queried and updated across the organization.
Best of all, you don’t need to deploy or manage individual MCP servers for each user or tool. Just turn it on and go. Learn more about the hosted MCP server in our documentation.
Centralized governance: Sync tags and descriptions to Databricks
We’re continuing to invest in making DataHub the single source of truth for your data governance.
With v0.3.12, we’re introducing a Databricks Metadata Sync Automation (Public Beta) that lets you push tags and descriptions from DataHub back to Databricks—covering tables, views, databases, and schemas.
Combined with metadata ingestion from Databricks, this unlocks bi-directional synchronization, ensuring governance context stays consistent across both platforms.
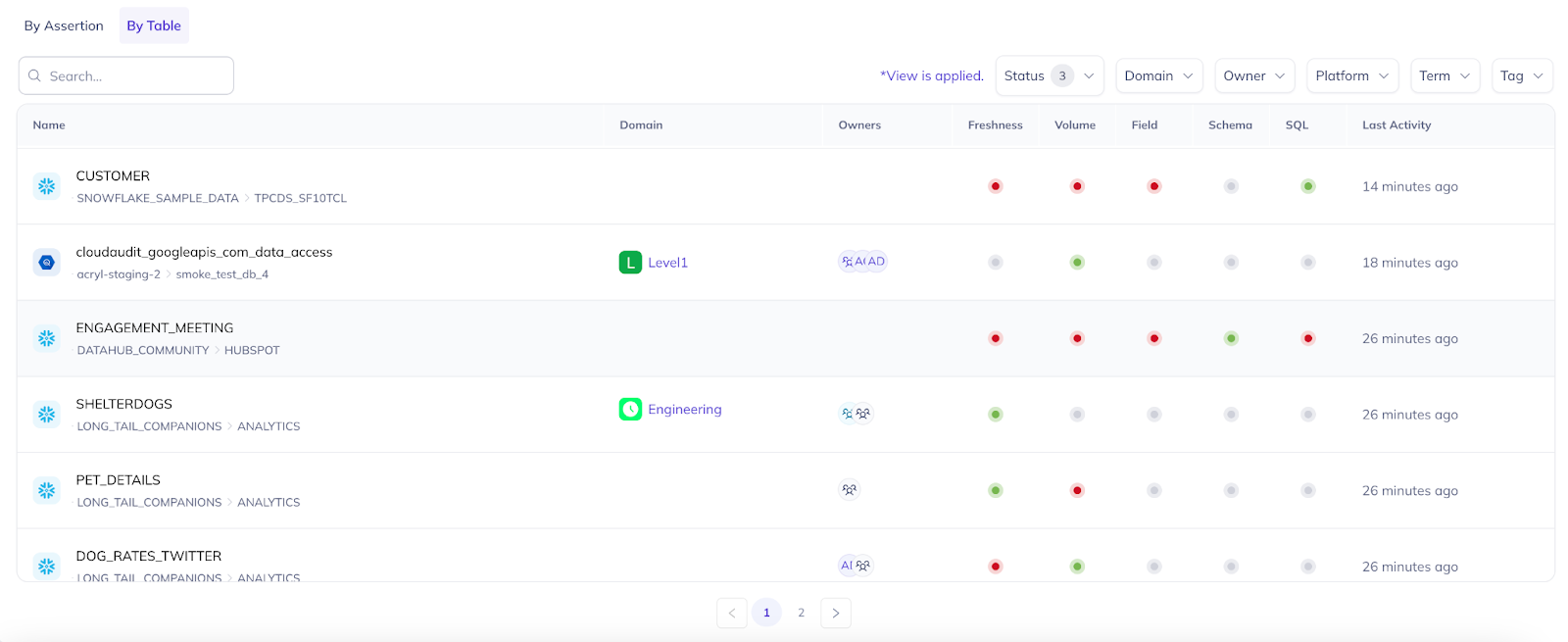
Data observability at scale: The new Data Health Dashboard
The Data Health Dashboard is your central hub for identifying, triaging, and resolving data quality issues across your organization.
In this release, we’re rolling out powerful new capabilities and refined filtering options to help you understand the health of your data at a glance—and act fast when things go wrong.
What’s new:
- Activity by assertion: Explore a log of results from all active data quality checks. Use rich filters to highlight your most problematic or most stable assertions. Slice by platform, domain, and more to focus on what matters most.
- Activity by table: Get a bird’s-eye view of your warehouse table health across key dimensions like Freshness, Volume, and Column-level checks. Quickly pinpoint tables that need attention.
- Incidents by asset: See which assets have open incidents or recent alert activity to stay ahead of potential downstream impacts.
This is a major step forward in our vision for DataHub as your central control plane for data observability—from detection, to triage, to resolution. Learn more in our docs.
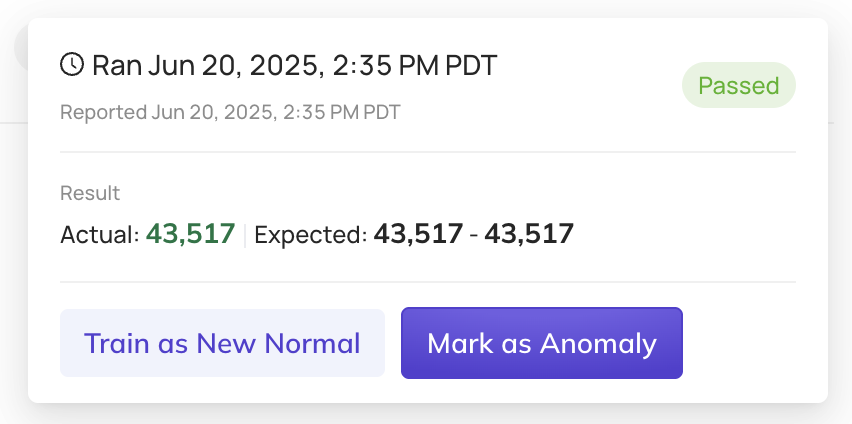
Tuning AI Smart Assertions with anomaly feedback
Smart Assertions use machine learning to detect data quality issues by learning from historical patterns in your data across Freshness, Volume, and Column health.
In v0.3.12, we’re giving you more control to fine-tune these models with explicit anomaly feedback—so your assertions get smarter over time.
Here’s what you can now do:
- Mark a failing assertion run as Not An Anomaly, to include it in training data for future model training runs
- Mark a passing assertion run as An Anomaly, to exclude it in training data for future model training runs.
- Establish new baselines when normal patterns shift by resetting the model training data based on the latest data points
This makes Smart Assertions more adaptive, accurate, and aligned with your evolving understanding of data quality. Learn more in our docs.
Lineage explorer for Data Pipelines
Data Pipelines have traditionally been a second class citizen within DataHub when it comes to the lineage experience. That changes today.
With this release, you can explore the full DAG topology and data lineage within a single experience for Data Pipelines from Airflow, Dagster, and more. This enables you to explore all pipeline tasks—and their data inputs and outputs—at a glance, increasing visibility into your data supply chain.

This experience is currently in Private Beta. If this looks useful to you, please reach out to your DataHub representative to enable this feature for testing.
Streamlined data source management
This release brings a fully overhauled Data Source Management experience, making it simpler to track, attribute, and delegate ingestion workflows.
Here’s what’s new:
- Run History tab: View all synchronization runs across your sources in one place, with the ability to filter down to the runs you care about—sorted chronologically for easy tracking.
- Source run attribution: See exactly who triggered each run, whether via the UI or CLI, to improve traceability and accountability.
- Data source ownership and delegation: Assign owners to individual data sources and configure granular policies to delegate view, edit, delete, and execute permissions across your organization.
All wrapped in a cleaner, more intuitive layout for creating, editing, and managing your sources. Learn more about managing data sources in our documentation.
AI documentation generation: Public beta
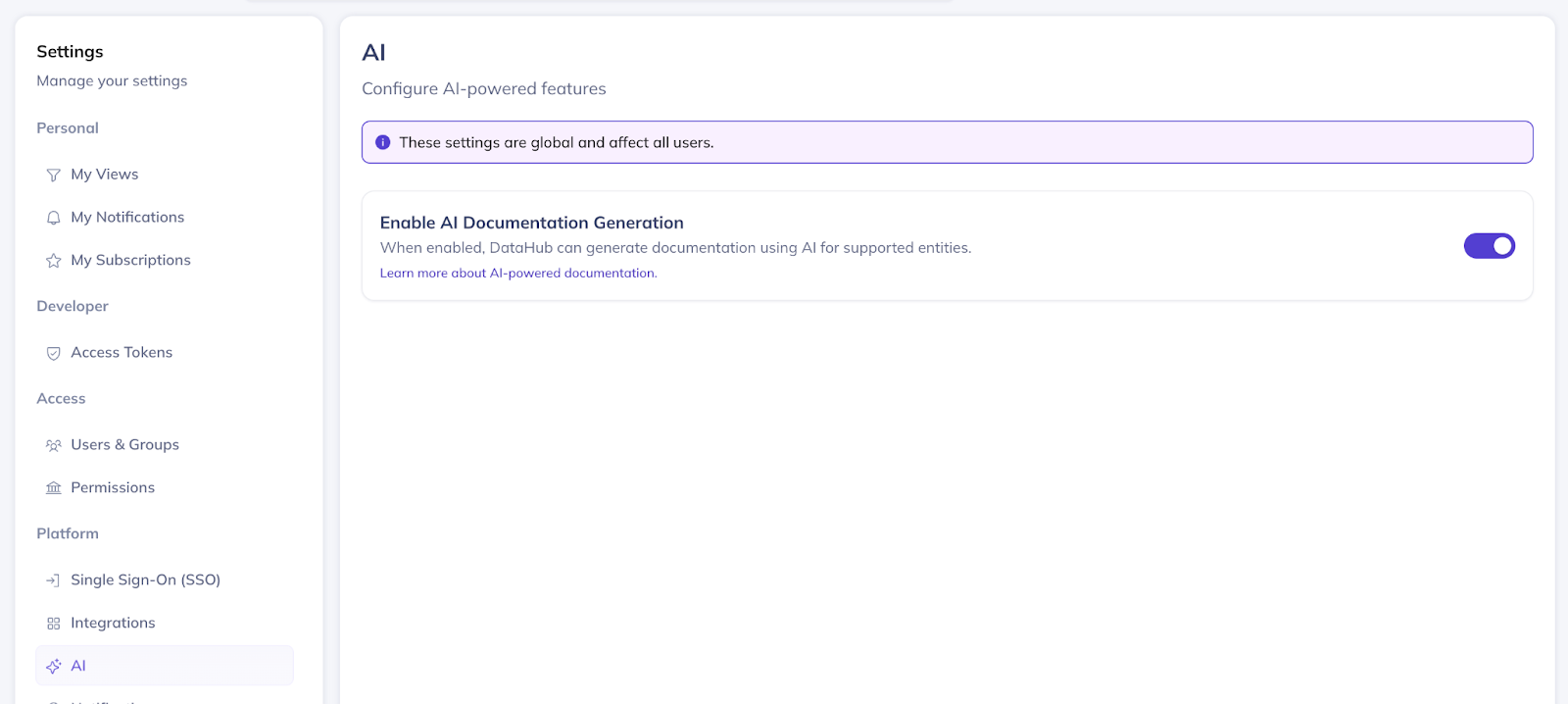
AI Documentation Generation is now in Public Beta, available to all customers by default!
Featuring an improved evaluation engine that prioritizes emphasis on impact, use cases, and table usage plus update patterns along with support for generating column documentation for large tables (up to 1000 columns).
Finally, we’ve introduced an Admin-level setting (available in Settings > AI) for globally enabling or disabling the AI documentation capability for end users.
Python SDK: Entities, data lineage, and search
We’ve been hard at work streamlining the developer experience in DataHub—making it easier than ever to programmatically manage your data landscape.
Three of the most common workflows we’ve focused on:
- Creating, updating, and deleting data assets
- Searching for data assets
- Registering asset- and column-level lineage
With v0.3.12, we’re introducing a simplified Python SDK that makes both tasks frictionless. Use clean, intuitive methods like:
- client.entities.create(…)
- client.lineage.add_lineage(…)
- client.search.get_urns(…)
Learn more about the simplified SDK experience:
Bug fixes and improvements
Here are a few more highly requested upgrades that made it into v0.3.12:
Data lineage
A refreshed lineage graph UI is now available in Private Beta.
- Lineage graph explorer has a modern, streamlined look & feel
- Lineage graph performance has been significantly improved, especially multi-hop expansion
Learn more about the lineage experience in our docs. Please reach out to your DataHub representative if you’re interested in trying out the new experience.
Data governance
- Compliance form notifications: Users can now be notified when they are assigned to complete data compliance tasks, enabling central data governance teams to more effectively distribute responsibility for achieving & maintaining data compliance at scale. Learn more in our docs.
- Change Proposals inbox within the Task Center has a brand new look and is now available to all DataHub Cloud customers in Public Beta! Learn more in our previous release blog.
- Enable and disable metadata tests on demand, directly from the UI.

DataHub admin
- DataHub Audit Events now integrate with AWS EventBridge for syncing audit log events at scale
Data sources and ingestion
- AWS Glue Connector now supports extraction of AWS LakeFormation Tags
More improvements
- Bug fix: Keep previously applied search filters when modifying queries on the search page
- DataHub Slack Discovery Assistant is now available in Private Beta. Please reach out to your DataHub representative if you’re interested in being a beta tester!
- API tracing: DataHub API responses now include trace IDs and timestamps
Backwards compatibility
There are no breaking changes in this release.
Remote Executor for data observability: If you’re actively running Observe monitors via a remote executor, this release requires upgrading to Remote Executor image v0.3.11.1-acryl or later. Reach out to your DataHub representative for additional support.
Let’s build together
We’re continuing to build DataHub Cloud in close partnership with our community and customers. Thank you for your feedback and support — it helps shape every release.
Want to learn more?
Join the conversation in the DataHub Slack Community
Explore the project, contribute ideas, and connect with thousands of practitioners in the DataHub Slack community.
Check our docs
Explore the full release notes in our docs.


